
Arañas SEO: Por qué son importantes para tu sitio
Las arañas son bots creados para el spam, que pueden causar muchos problemas a tu negocio. Aprende más sobre ellas en el artículo.
5 min de lectura
SEO
DigitalMarketing
+3
Descubre por qué a los rastreadores web se les llama arañas, cómo funcionan y su papel crucial en la indexación de motores de búsqueda. Conoce los mecanismos técnicos detrás del rastreo web en 2025.
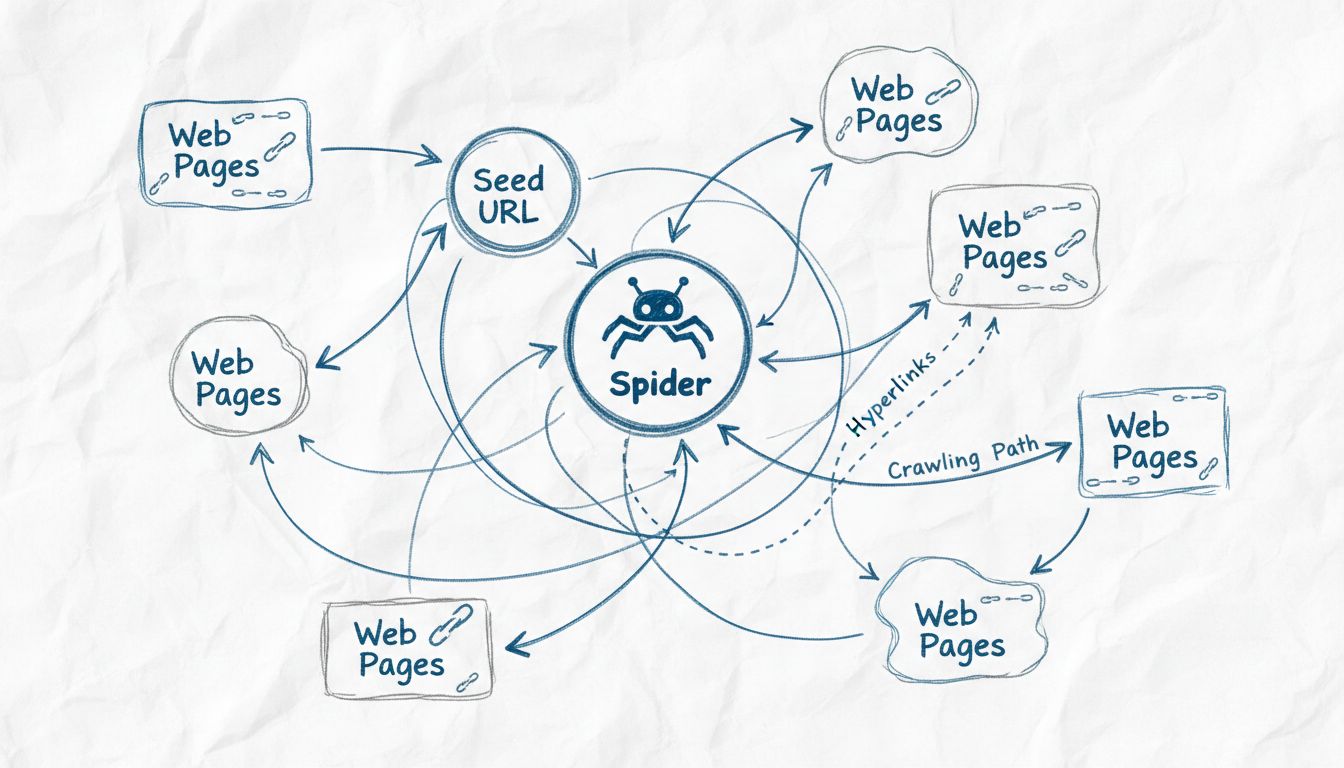
A los rastreadores web se les llama arañas porque recorren sistemáticamente la web siguiendo enlaces de una página a otra, similar a cómo una araña navega su telaraña. El término 'araña' es una metáfora adecuada para estos bots automatizados que atraviesan la red interconectada de sitios web para descubrir, indexar y organizar contenido web para los motores de búsqueda.
El término “araña” para los rastreadores web se origina en una ingeniosa comparación metafórica entre la forma en que estos bots automatizados navegan por internet y cómo las arañas reales recorren sus telarañas. Así como una araña teje una compleja red para atrapar y organizar información sobre su entorno, los rastreadores web atraviesan la red interconectada de hipervínculos en la World Wide Web para descubrir, analizar y organizar contenido digital. La metáfora es especialmente acertada porque ambas entidades operan sistemáticamente a través de redes complejas, siguiendo caminos para llegar a nuevos destinos y recopilar información. Esta convención de nombres se ha arraigado tanto en la tecnología que los términos “araña”, “rastreadores” y “bot” ahora se usan indistintamente cuando se habla de tecnología de indexación web. La similitud visual y conceptual entre la telaraña de una araña y la estructura de internet hace que esta terminología sea tanto intuitiva como memorable para profesionales técnicos y usuarios en general.
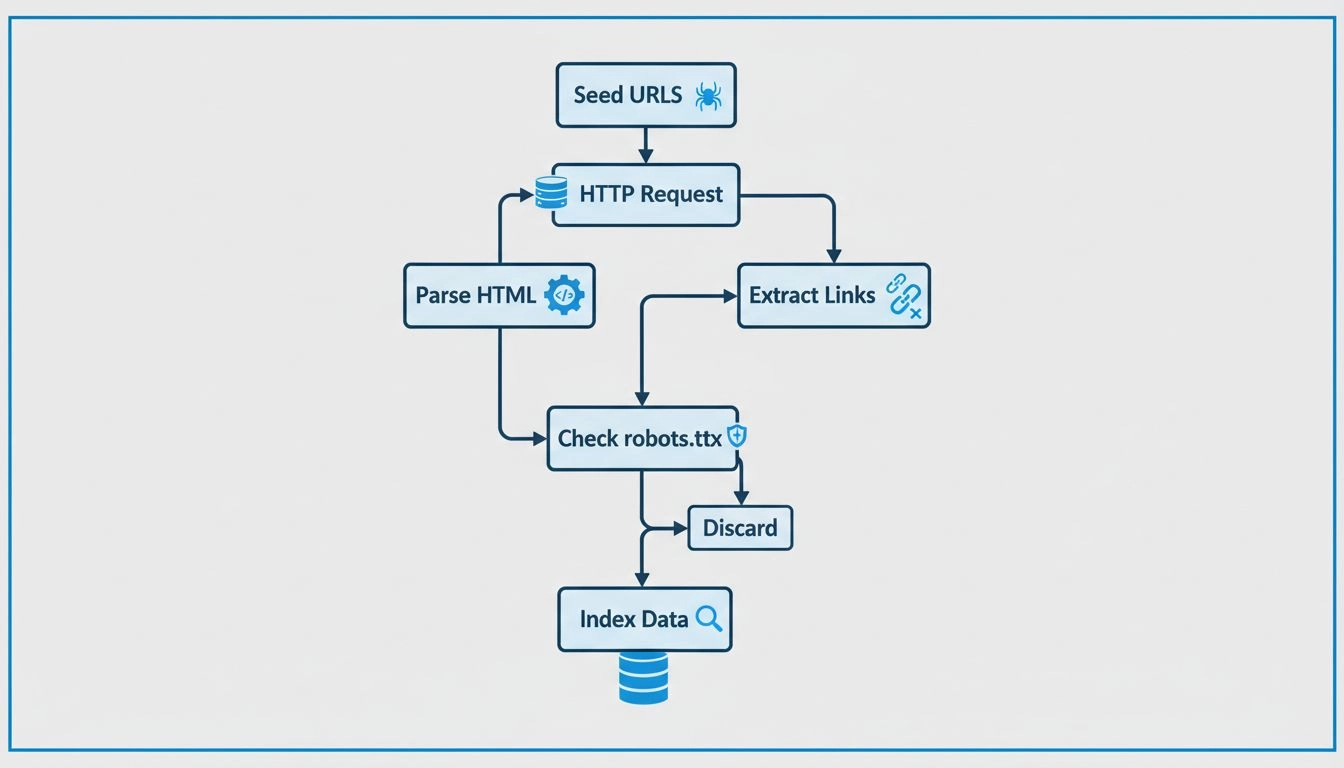
Las arañas web operan mediante un proceso sofisticado pero sistemático que comienza con un punto de entrada denominado “URL semilla”. Desde este punto de partida, la araña analiza el código HTML de la página web, extrayendo todos los hipervínculos presentes en esa página. Luego, la araña sigue estos enlaces hacia nuevas páginas, repitiendo el proceso de manera continua para expandir su alcance a través de la web. Este enfoque metódico permite a las arañas descubrir millones de páginas interconectadas sin necesidad de dirección manual o intervención humana. La araña mantiene lo que se conoce como “frontera de rastreo”, que es esencialmente una cola de URLs que han sido descubiertas pero aún no visitadas. Según políticas y algoritmos de rastreo específicos, la araña prioriza qué URLs visitar a continuación, considerando factores como la importancia de la página, la frecuencia de actualización y la relevancia para los objetivos de indexación del motor de búsqueda.
Configura el seguimiento avanzado en minutos. No se requiere tarjeta de crédito.
Las arañas web modernas están construidas sobre una arquitectura técnica sofisticada que les permite procesar grandes cantidades de datos de manera eficiente. Los componentes principales de un rastreador web incluyen el sistema de gestión de la frontera de URLs, que organiza y prioriza las URLs para rastrear; el mecanismo de obtención, que descarga el contenido de las páginas a gran velocidad; el motor de análisis, que extrae enlaces y metadatos del HTML; y el sistema de indexación, que almacena la información procesada para su recuperación en búsquedas. Las arañas web también deben implementar políticas de cortesía para evitar sobrecargar los servidores de destino con solicitudes excesivas, políticas de revisita para determinar con qué frecuencia se deben volver a rastrear las páginas en busca de actualizaciones, y políticas de selección para decidir qué enlaces son más valiosos para seguir. Las arañas contemporáneas han evolucionado para manejar contenido en JavaScript y AJAX, aunque todavía priorizan el HTML estándar para un descubrimiento fiable de contenido. La naturaleza distribuida del rastreo moderno significa que las arañas a gran escala operan en múltiples servidores simultáneamente, lo que les permite rastrear diferentes sitios web en paralelo y aumentar drásticamente su eficiencia y cobertura general.
Aunque los términos “araña” y “rastreadores” suelen usarse indistintamente, es importante entender que representan la misma tecnología con diferentes convenciones de denominación. Sin embargo, las arañas web difieren significativamente de los scrapers web, que a veces se confunden con los rastreadores. La principal diferencia radica en su propósito y alcance: los rastreadores web se centran en recopilar información general sobre los sitios web y su estructura, siguiendo enlaces de manera amplia por la web para construir índices completos. Las arañas web, cuando son utilizadas específicamente por los motores de búsqueda, se concentran en indexar contenido textual para hacerlo visible y accesible en las búsquedas. Los scrapers web, en cambio, son herramientas de precisión diseñadas para extraer elementos de datos específicos de los sitios web, como precios de productos, información de contacto o reseñas. Los scrapers suelen centrarse en sitios web o tipos de datos particulares en lugar de rastrear ampliamente la web. Además, los rastreadores y las arañas generalmente respetan los archivos robots.txt y los términos de servicio de los sitios web, mientras que los scrapers pueden operar sin tales restricciones. Comprender estas diferencias es crucial para los propietarios y desarrolladores de sitios web que necesitan gestionar cómo su contenido es accedido e indexado por sistemas automatizados.
Sé el primero en conocer las nuevas funciones y actualizaciones del producto.
Las arañas web son absolutamente fundamentales para el funcionamiento de los motores de búsqueda y para aportar valor a los usuarios en todo el mundo. Sin arañas rastreando e indexando continuamente el contenido web, los motores de búsqueda no tendrían forma de saber qué sitios existen, qué contenido contienen o cuán relevante puede ser ese contenido para las consultas de los usuarios. Cuando una araña rastrea una página web, evalúa numerosos factores, incluyendo la estructura de la página, la relevancia del contenido, el uso de palabras clave y señales de experiencia de usuario. Esta información se almacena luego en enormes índices que los motores de búsqueda utilizan para asociar las consultas de los usuarios con los resultados más relevantes. La calidad y frecuencia del rastreo de las arañas impacta directamente en qué tan rápido aparece el contenido nuevo en los resultados de búsqueda y cuán precisamente los motores pueden clasificar las páginas. Motores de búsqueda como Google, Bing, Baidu y Yahoo mantienen sus propios bots de araña propietarios—Googlebot, Bingbot, Baiduspider y Slurp respectivamente—cada uno con algoritmos y estrategias de rastreo únicos optimizados para los objetivos y bases de usuarios de su motor de búsqueda específico.
| Bot Araña | Motor de Búsqueda | Función Principal | Estrategia de Rastreo | Características Clave |
|---|---|---|---|---|
| Googlebot | Indexar páginas web para Google Search | Rastreo distribuido con variantes para móvil y escritorio | Maneja JavaScript, prioriza la indexación mobile-first, respeta el presupuesto de rastreo | |
| Bingbot | Microsoft Bing | Indexar páginas web para Bing Search | Rastreo en paralelo en múltiples servidores | Uso eficiente del ancho de banda, respeta robots.txt, soporta múltiples tipos de contenido |
| Baiduspider | Baidu | Indexar páginas web para Baidu Search | Optimizado para contenido en chino | Especializado para contenido web asiático, maneja chino simplificado y tradicional |
| DuckDuckBot | DuckDuckGo | Indexar páginas web para búsquedas enfocadas en privacidad | Rastreo respetuoso con énfasis en la privacidad | Mínima recopilación de datos, respeta las preferencias de privacidad del usuario |
| YandexBot | Yandex | Indexar páginas web para Yandex Search | Rastreo distribuido con optimización regional | Optimizado para contenido ruso y de Europa del Este |
Los propietarios de sitios web disponen de varias herramientas y estrategias para optimizar cómo las arañas rastrean e indexan su contenido. Crear un archivo sitemap.xml completo proporciona a las arañas una hoja de ruta clara de todas las páginas que deben ser indexadas, mejorando significativamente la eficiencia del rastreo y asegurando que no se omitan páginas importantes. Optimizar las metaetiquetas, incluyendo títulos y descripciones, ayuda a las arañas a comprender el contenido de la página y mejora la forma en que las páginas aparecen en los resultados de búsqueda. Implementar un archivo robots.txt bien estructurado permite a los propietarios guiar a las arañas hacia el contenido importante y alejarlas de páginas que no deben ser indexadas, como paneles de administración o contenido duplicado. Actualizar y añadir contenido fresco regularmente anima a las arañas a visitar los sitios más a menudo, manteniendo los índices actualizados y mejorando la visibilidad en las búsquedas. Los propietarios también deben asegurarse de que la arquitectura de su sitio sea limpia y lógica, con una navegación jerárquica clara que facilite a las arañas descubrir todas las páginas. Mejorar la velocidad de carga de las páginas es fundamental porque las arañas tienen presupuestos de rastreo limitados—la cantidad de recursos que los motores de búsqueda asignan para rastrear un sitio específico—y las páginas más rápidas permiten que las arañas rastreen más contenido dentro de ese presupuesto.
A pesar de su sofisticación, las arañas web enfrentan numerosos desafíos técnicos que pueden limitar su efectividad. El contenido dinámico generado por JavaScript representa un obstáculo importante, ya que no todas las arañas pueden ejecutar código JavaScript para mostrar las páginas tal como las ven los usuarios. Las limitaciones de tasa impuestas por los sitios restringen cuántas solicitudes pueden hacer las arañas en un periodo de tiempo dado, lo que puede impedir la indexación completa de sitios web grandes. Los desafíos CAPTCHA y otras medidas anti-bots pueden bloquear el acceso de las arañas al contenido, aunque las arañas legítimas de los motores de búsqueda suelen estar en listas blancas. El contenido duplicado en múltiples URLs confunde a las arañas sobre qué versión debe ser indexada y clasificada, lo que puede diluir la visibilidad en las búsquedas. Las trampas para rastreadores—bucles infinitos intencionados o accidentales en la estructura del sitio—pueden desperdiciar recursos de la araña y consumir el presupuesto de rastreo sin una indexación productiva. Además, el crecimiento exponencial del contenido web significa que las arañas no pueden rastrear e indexar todo, requiriendo algoritmos sofisticados para priorizar qué contenido es más importante para indexar. Las páginas protegidas por contraseña y el contenido autenticado permanecen en gran medida inaccesibles para las arañas públicas, limitando la indexación de contenido privado o para miembros.
La tecnología de las arañas web sigue evolucionando rápidamente a medida que internet crece y se vuelve más compleja. Las arañas modernas son cada vez más capaces de manejar tecnologías web avanzadas, incluidas aplicaciones de una sola página, aplicaciones web progresivas y renderizado dinámico de contenido. La inteligencia artificial y el aprendizaje automático se están integrando en los algoritmos de las arañas para comprender mejor el contexto del contenido, la intención del usuario y la calidad de las páginas. El auge de la inteligencia artificial generativa ha creado nuevas demandas para el rastreo web, ya que los sistemas de IA requieren información constantemente actualizada, relevante y precisa para funcionar eficazmente. Los rastreadores empresariales se han vuelto cada vez más sofisticados, permitiendo a las empresas rastrear sus propios sitios para funcionalidad de búsqueda interna, gestión de contenidos y monitoreo de rendimiento. El enfoque en la eficiencia del rastreo se ha intensificado a medida que los sitios web crecen en tamaño y complejidad, y ahora las arañas implementan algoritmos de priorización más inteligentes para maximizar el valor de cada solicitud de rastreo. Las consideraciones de privacidad también están moldeando el desarrollo de las arañas, con un énfasis creciente en respetar la privacidad del usuario sin dejar de permitir el descubrimiento e indexación efectiva del contenido. Mirando hacia adelante, es probable que las arañas web sean aún más inteligentes y eficientes, aprovechando tecnologías avanzadas para navegar un panorama digital cada vez más complejo, respetando al mismo tiempo las políticas de los sitios web y la privacidad de los usuarios.
Así como las arañas web rastrean e indexan sistemáticamente toda la web, PostAffiliatePro rastrea y optimiza sistemáticamente cada relación de afiliados en tu red. Nuestra avanzada tecnología de seguimiento asegura que ninguna comisión quede sin registrar y que no se pierda ninguna oportunidad.
Las arañas son bots creados para el spam, que pueden causar muchos problemas a tu negocio. Aprende más sobre ellas en el artículo.
Los rastreadores acumulan datos e información de internet visitando sitios web y leyendo las páginas. Descubre más sobre ellos.
Aprende cómo funcionan los rastreadores web, desde las URLs semilla hasta la indexación. Comprende el proceso técnico, los tipos de rastreadores, las reglas de ...
Únete a nuestra comunidad de clientes satisfechos y brinda excelente soporte al cliente con Post Affiliate Pro.
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.