
Rastreadores y su papel en el posicionamiento en buscadores
Los rastreadores acumulan datos e información de internet visitando sitios web y leyendo las páginas. Descubre más sobre ellos.
6 min de lectura
SEO
Crawlers
+4
Aprende cómo funcionan los rastreadores web, desde las URLs semilla hasta la indexación. Comprende el proceso técnico, los tipos de rastreadores, las reglas de robots.txt y cómo los rastreadores impactan en el SEO y el marketing de afiliados.
Los rastreadores web funcionan enviando solicitudes HTTP a sitios web a partir de URLs semilla, siguiendo hipervínculos para descubrir nuevas páginas, analizando el contenido HTML para extraer información, respetando las reglas de robots.txt y almacenando los datos recopilados en índices consultables. Visitan sistemáticamente páginas, extraen metadatos y enlaces, y repiten el proceso para mantener actualizadas las bases de datos de los motores de búsqueda.
Los rastreadores web, también conocidos como spiders o bots, son programas automatizados que navegan sistemáticamente por internet para descubrir, descargar y analizar contenido web. Estos agentes inteligentes forman la columna vertebral de la infraestructura de los motores de búsqueda, permitiendo a plataformas como Google, Bing y otros servicios de búsqueda construir índices integrales de miles de millones de páginas web. El objetivo principal de los rastreadores web es recopilar y organizar información de los sitios web para que los motores de búsqueda puedan recuperar rápidamente resultados relevantes cuando los usuarios realizan búsquedas. Sin los rastreadores web, los motores de búsqueda no tendrían forma de descubrir contenido nuevo ni de mantener actualizados sus índices con la información más reciente disponible en línea.
La importancia de los rastreadores web va mucho más allá de la simple funcionalidad de búsqueda. Sirven como base para numerosas aplicaciones digitales, incluyendo sitios web de comparación de precios, agregadores de contenido, plataformas de investigación de mercado, herramientas de análisis SEO y servicios de archivo web. Para los especialistas en marketing de afiliados y operadores de redes como los que utilizan PostAffiliatePro, entender cómo funcionan los rastreadores es esencial para asegurar que el contenido de afiliados, las páginas de productos y los materiales promocionales sean descubiertos e indexados correctamente por los motores de búsqueda. Esta visibilidad impacta directamente en el tráfico orgánico, la generación de prospectos y, en última instancia, las oportunidades de comisión de afiliados.
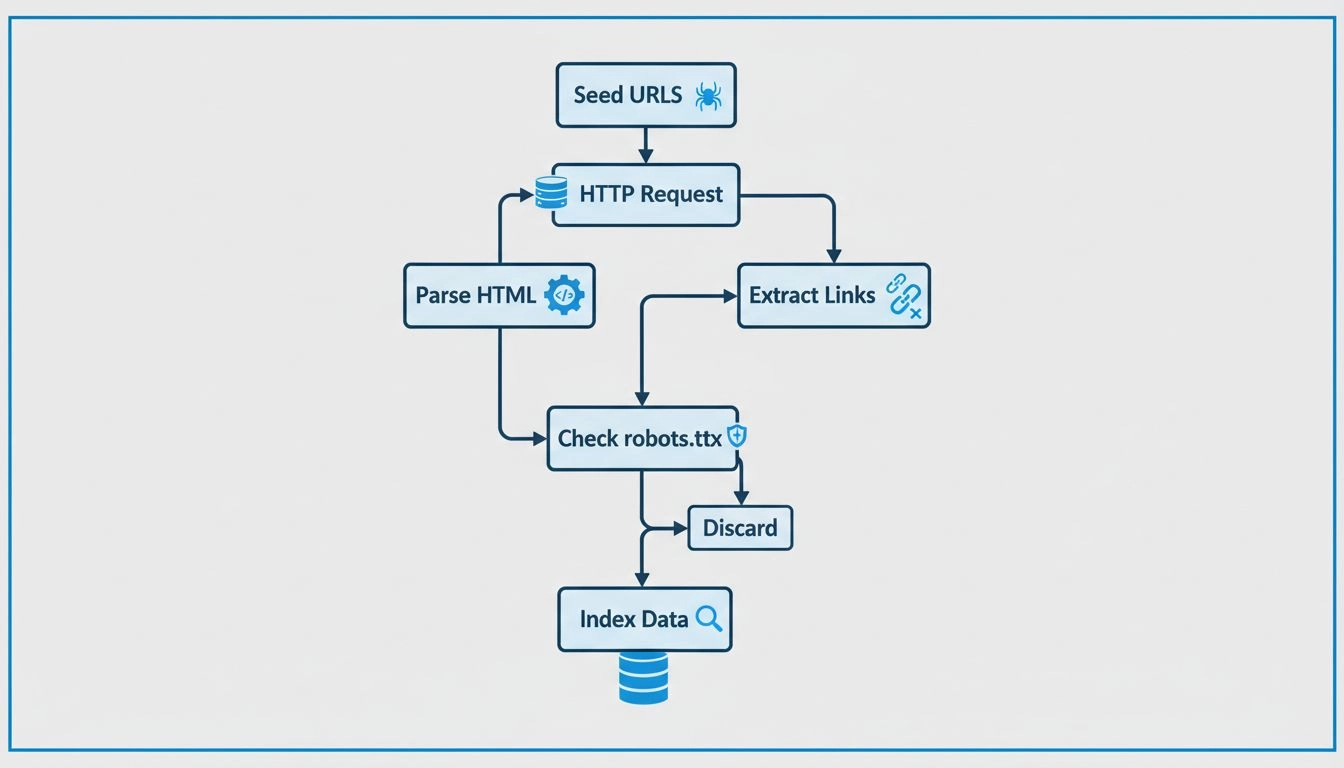
Los rastreadores web siguen un proceso metódico y estructurado para explorar sistemáticamente internet. El proceso comienza con URLs semilla, que son puntos de partida conocidos como URLs de inicio, mapas del sitio XML o páginas rastreadas previamente. Estas URLs semilla sirven como punto de entrada para el recorrido del rastreador por la web. El rastreador mantiene una cola de URLs por visitar, a menudo llamada “frontera de rastreo”, que crece continuamente a medida que se descubren nuevos enlaces durante el proceso de rastreo.
Cuando un rastreador llega a una URL, envía una solicitud HTTP al servidor web que aloja esa página. El servidor responde enviando el contenido HTML de la página, de forma similar a como un navegador web carga una página cuando la visitas. El rastreador entonces analiza este código HTML para extraer información valiosa, incluyendo el contenido de texto de la página, metaetiquetas (como título y descripción), imágenes, videos y, lo más importante, hipervínculos a otras páginas. Esta extracción de enlaces es crucial porque permite al rastreador descubrir nuevas URLs que aún no han sido visitadas, las cuales se añaden a la cola de rastreo para visitas futuras.
| Etapa del proceso del rastreador | Descripción | Acciones clave |
|---|---|---|
| Inicialización | Comenzar el proceso de rastreo | Cargar URLs semilla, inicializar la cola de rastreo |
| Solicitud y recuperación | Obtener contenido de la página | Enviar solicitudes HTTP, recibir respuestas HTML |
| Análisis HTML | Analizar la estructura de la página | Extraer texto, metadatos, enlaces, medios |
| Extracción de enlaces | Encontrar nuevas URLs | Identificar hipervínculos, añadir a la cola de rastreo |
| Verificación de robots.txt | Respetar las reglas del sitio | Verificar permisos de rastreo antes de visitar |
| Almacenamiento de contenido | Guardar información | Indexar datos en una base de datos consultable |
| Priorización | Determinar próximas páginas | Clasificar URLs por importancia y relevancia |
| Repetición | Continuar el ciclo | Procesar la siguiente URL en la cola |
Antes de visitar una nueva URL en un dominio, los rastreadores responsables verifican el archivo robots.txt ubicado en el directorio raíz de ese dominio. Este archivo contiene instrucciones que los propietarios de sitios web utilizan para comunicarse con los rastreadores sobre qué páginas pueden rastrearse y cuáles deben evitarse. Por ejemplo, un propietario de sitio web podría usar robots.txt para impedir que los rastreadores accedan a páginas sensibles, contenido duplicado o secciones con muchos recursos que podrían sobrecargar sus servidores. La mayoría de los rastreadores legítimos de motores de búsqueda respetan estas instrucciones para mantener buenas relaciones con los propietarios de sitios y evitar causar problemas de rendimiento.
Configura el seguimiento avanzado en minutos. No se requiere tarjeta de crédito.
Los rastreadores web modernos han evolucionado significativamente para manejar la complejidad de los sitios web contemporáneos. Hoy en día, muchos sitios web utilizan JavaScript para generar contenido dinámicamente después de que la página ha cargado, lo que significa que la respuesta HTML inicial no contiene todo el contenido de la página. Los rastreadores avanzados ahora utilizan navegadores sin interfaz gráfica (headless browsers) para renderizar JavaScript y capturar contenido cargado dinámicamente que no sería visible para los rastreadores tradicionales. Esta capacidad es esencial para rastrear aplicaciones de una sola página, paneles interactivos y aplicaciones web modernas que dependen en gran medida del renderizado del lado del cliente.
Los rastreadores implementan sofisticados algoritmos de priorización para hacer un uso eficiente de su presupuesto de rastreo—el número limitado de páginas que pueden rastrear en un periodo de tiempo determinado. Estos algoritmos consideran múltiples factores, incluyendo la autoridad de la página (determinada por la calidad y cantidad de enlaces entrantes), la estructura de enlaces internos, la frescura del contenido, el volumen de tráfico y la reputación del dominio. Las páginas de alta autoridad y el contenido actualizado con frecuencia reciben visitas de rastreo más frecuentes, mientras que las páginas menos importantes o estáticas pueden ser visitadas con menos frecuencia o ignoradas por completo. Esta priorización inteligente asegura que los rastreadores enfoquen sus recursos en el contenido más valioso y que cambia con frecuencia.
El retraso en el rastreo y la limitación de velocidad son mecanismos importantes que evitan que los rastreadores sobrecarguen los servidores web. Los rastreadores responsables implementan pausas entre solicitudes y respetan las directivas de crawl-delay especificadas en los archivos robots.txt. Este comportamiento educado de rastreo protege el rendimiento del sitio y la experiencia del usuario al garantizar que el tráfico de los rastreadores no consuma recursos excesivos del servidor. Los sitios web que cargan lentamente o devuelven errores pueden experimentar una menor frecuencia de rastreo, ya que los rastreadores disminuyen automáticamente la velocidad para evitar causar problemas.
Distintos tipos de rastreadores web cumplen propósitos específicos en el ecosistema digital. Los rastreadores web generales son desplegados por los principales motores de búsqueda para rastrear internet en su totalidad de manera indiscriminada, creando índices integrales que alimentan los resultados de búsqueda. Estos rastreadores están diseñados para una cobertura máxima y operan continuamente para descubrir contenido nuevo y actualizar los índices existentes. Los rastreadores verticales o especializados se enfocan en industrias o tipos de contenido específicos, como rastreadores de empleo que buscan en portales de empleo, rastreadores de comparación de precios que recopilan datos de precios de sitios de comercio electrónico, o rastreadores de investigación que indexan artículos académicos y publicaciones científicas.
Los rastreadores incrementales se especializan en la eficiencia al enfocarse solo en contenido nuevo o recientemente modificado en lugar de volver a rastrear sitios completos repetidamente. Este enfoque reduce significativamente la carga del servidor y el consumo de ancho de banda mientras mantiene los índices relativamente actualizados. Los rastreadores enfocados usan algoritmos sofisticados para buscar contenido sobre temas o palabras clave específicos, priorizando inteligentemente las páginas que probablemente contengan información relevante. Los rastreadores en tiempo real monitorean continuamente sitios web y actualizan sus datos recopilados en tiempo real o casi en tiempo real, siendo ideales para aplicaciones de agregación de noticias y monitoreo de redes sociales.
Los rastreadores paralelos y rastreadores distribuidos representan el extremo de infraestructura avanzada del espectro de rastreadores. Los rastreadores paralelos operan en múltiples máquinas o hilos simultáneamente para aumentar drásticamente la velocidad y el rendimiento del rastreo. Los rastreadores distribuidos reparten la carga de trabajo entre varios servidores o centros de datos, permitiéndoles procesar cantidades masivas de datos de manera eficiente. Grandes motores de búsqueda como Google utilizan arquitecturas de rastreadores distribuidos para manejar los miles de millones de páginas en internet.
Sé el primero en conocer las nuevas funciones y actualizaciones del producto.
Los rastreadores web juegan un papel fundamental en la optimización para motores de búsqueda porque determinan qué páginas se indexan y cómo los motores de búsqueda entienden tu contenido. Si los rastreadores no pueden acceder a tus páginas, esas páginas no aparecerán en los resultados de búsqueda sin importar su calidad o relevancia. Problemas comunes de rastreo que impiden la indexación adecuada incluyen páginas bloqueadas por directivas de robots.txt, enlaces internos rotos que llevan a errores 404, tiempos de carga lentos que hacen que los rastreadores agoten el tiempo de espera, y problemas de renderizado JavaScript que impiden a los rastreadores ver contenido generado dinámicamente.
Los propietarios de sitios web pueden optimizar el acceso de los rastreadores a través de varias estrategias clave. Una arquitectura de sitio clara con jerarquías de navegación lógicas ayuda a los rastreadores a entender la relación e importancia de las páginas. El enlazado interno señala a los rastreadores cuáles páginas son más importantes y ayuda a distribuir eficientemente el presupuesto de rastreo a través del sitio. Los sitemaps XML listan explícitamente todas las páginas importantes, asegurando que los rastreadores no se pierdan contenido incluso en sitios grandes o complejos. Tiempos de carga rápidos animan a los rastreadores a visitar más páginas dentro de su presupuesto asignado, mientras que contenido fresco y actualizado regularmente indica que un sitio merece visitas de rastreo más frecuentes.
Para los especialistas en marketing de afiliados que utilizan plataformas como PostAffiliatePro, asegurar el acceso adecuado de los rastreadores es fundamental para atraer tráfico orgánico al contenido de afiliados. Cuando tus páginas de productos de afiliados, artículos comparativos y contenido promocional son rastreados e indexados correctamente, tienen la oportunidad de posicionarse en los resultados de búsqueda y atraer tráfico calificado. Una mala rastreabilidad puede resultar en oportunidades de indexación perdidas y menor visibilidad para tus ofertas de afiliado.
Los propietarios de sitios web tienen varios mecanismos para controlar cómo interactúan los rastreadores con sus sitios. El archivo robots.txt es la principal herramienta, contiene directivas que especifican qué user-agents (tipos de rastreadores) pueden acceder a qué partes del sitio web. Un archivo robots.txt bien configurado puede evitar que los rastreadores desperdicien recursos en contenido duplicado, entornos de prueba o páginas que consumen muchos recursos, permitiéndoles rastrear libremente el contenido importante. La metaetiqueta robots aparece en el HTML de páginas individuales y proporciona control a nivel de página, permitiendo excluir páginas específicas de la indexación o indicar que sus enlaces deben ser ignorados.
El atributo de enlace nofollow indica a los rastreadores que no sigan hipervínculos específicos, útil para evitar que los rastreadores sigan enlaces a sitios externos no confiables o a contenido generado por usuarios. Estos mecanismos de control trabajan conjuntamente para ofrecer a los propietarios de sitios un control detallado sobre el comportamiento de los rastreadores, mientras mantienen buenas relaciones con los motores de búsqueda. Sin embargo, es importante tener en cuenta que los scrapers maliciosos y bots agresivos suelen ignorar estas directivas por completo, por lo que a veces son necesarias medidas de seguridad adicionales como la limitación de velocidad y la detección de bots.
Para los operadores de redes de afiliados y los especialistas en marketing, comprender el comportamiento de los rastreadores web impacta directamente en el éxito del negocio. Los rastreadores determinan la visibilidad de las páginas de productos de afiliados, contenido comparativo y materiales promocionales en los resultados de búsqueda. Cuando los usuarios de PostAffiliatePro optimizan sus sitios de afiliados para un rastreo adecuado, aumentan la probabilidad de que su contenido sea descubierto por los motores de búsqueda y posicionado para palabras clave relevantes. Esta visibilidad orgánica dirige tráfico calificado hacia las ofertas de afiliado, incrementando las oportunidades de conversión y las ganancias por comisión.
Las redes de afiliados se benefician de la actividad de los rastreadores de múltiples formas. Los rastreadores de motores de búsqueda ayudan a distribuir el contenido de afiliados en internet, aumentando el reconocimiento de marca y el alcance. Los rastreadores también permiten que sitios de comparación de precios y agregadores de contenido descubran y destaquen productos de afiliados, creando fuentes adicionales de tráfico. Sin embargo, los especialistas en marketing de afiliados también deben estar atentos a rastreadores y scrapers maliciosos que pueden copiar contenido de afiliados o participar en fraude de clics. Implementar una adecuada limitación de velocidad, detección de bots y medidas de protección de contenido ayuda a proteger la integridad de la red de afiliados, mientras se permite el funcionamiento adecuado de los rastreadores legítimos.
PostAffiliatePro proporciona capacidades de seguimiento e informes integrales que complementan una correcta optimización para rastreadores. Al asegurar que tu contenido de afiliado sea rastreado e indexado correctamente, combinado con el avanzado seguimiento y análisis de PostAffiliatePro, puedes maximizar la visibilidad y rentabilidad de tu red de afiliados. El seguimiento de comisiones en tiempo real y los informes inteligentes de la plataforma te ayudan a entender qué canales de afiliados generan el tráfico más valioso, permitiéndote optimizar tu estrategia de red en consecuencia.
Así como los rastreadores web descubren e indexan contenido sistemáticamente, PostAffiliatePro rastrea y optimiza sistemáticamente tus relaciones de afiliados. Nuestra plataforma ofrece seguimiento en tiempo real, informes integrales y gestión inteligente de comisiones para ayudarte a construir una red de afiliados próspera.
Los rastreadores acumulan datos e información de internet visitando sitios web y leyendo las páginas. Descubre más sobre ellos.
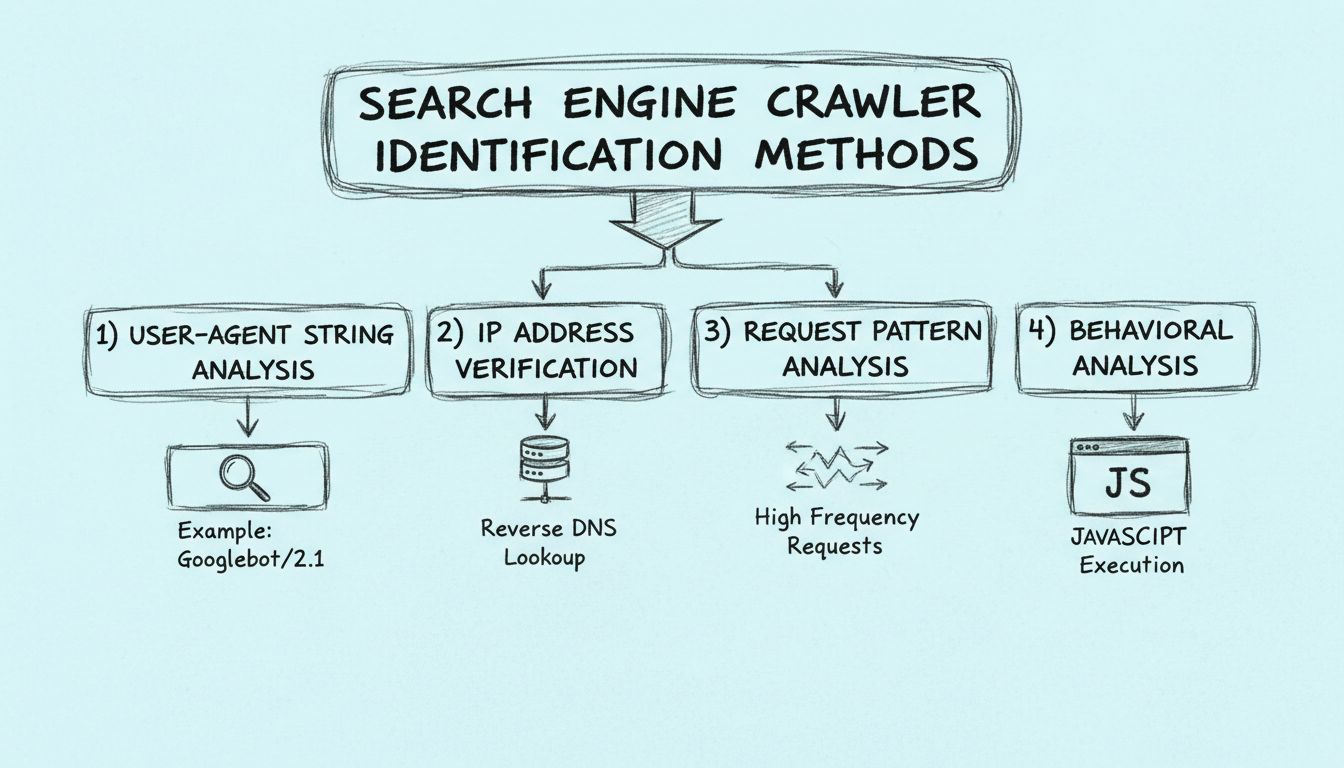
Aprende cómo identificar rastreadores de motores de búsqueda mediante cadenas de user-agent, direcciones IP, patrones de solicitud y análisis de comportamiento....
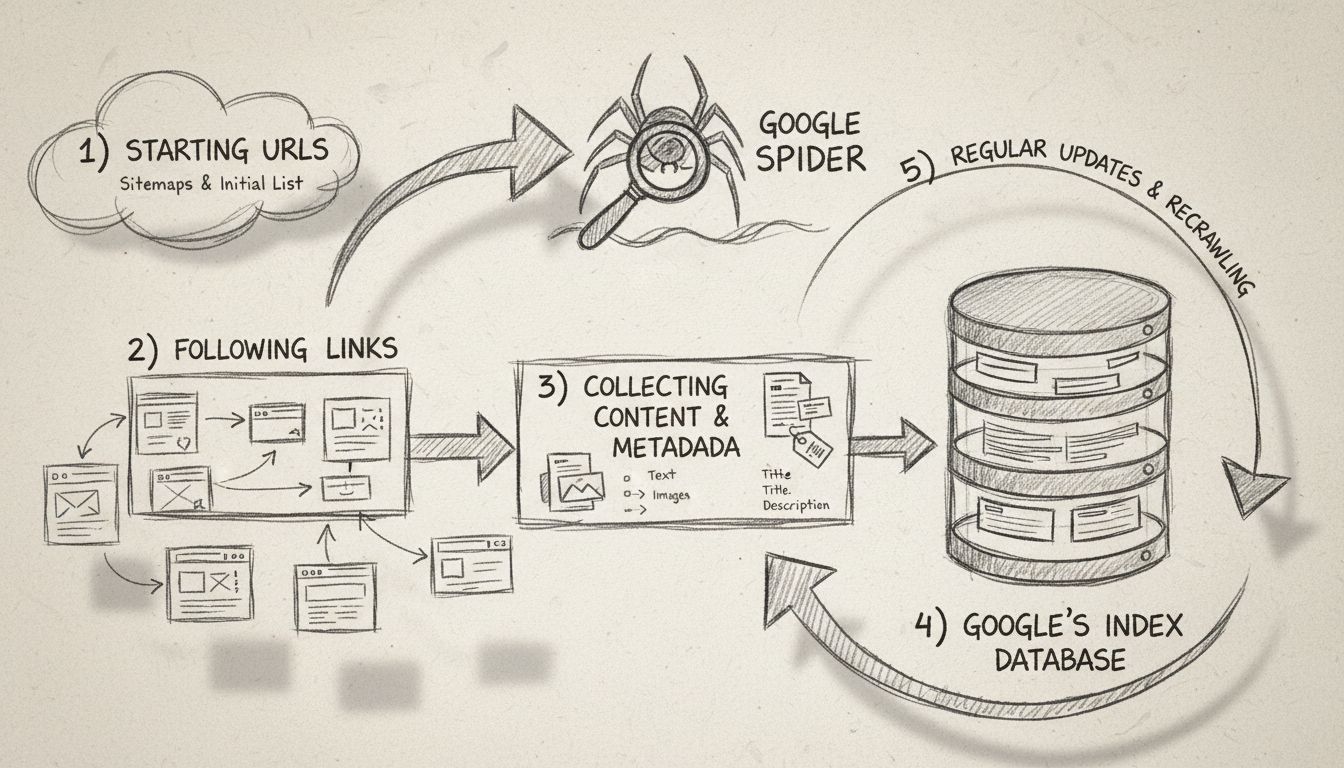
Aprende qué es Google Spider (Googlebot), cómo rastrea e indexa sitios web y por qué es esencial para el SEO. Descubre cómo optimizar tu sitio para un mejor ras...
Únete a nuestra comunidad de clientes satisfechos y brinda excelente soporte al cliente con Post Affiliate Pro.
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.