¿Es el contenido duplicado malo para el SEO? Guía completa sobre el impacto del contenido duplicado
Descubre por qué el contenido duplicado perjudica el SEO, cómo afecta al posicionamiento y soluciones comprobadas como etiquetas canónicas y redirecciones 301 para resolver problemas de contenido duplicado en 2025.
¿El contenido duplicado es malo para el SEO?
Sí, el contenido duplicado puede afectar negativamente al SEO al confundir a los motores de búsqueda sobre qué versión posicionar, diluir la autoridad de los enlaces entre varias URLs, desperdiciar el presupuesto de rastreo y, potencialmente, permitir que contenido copiado supere a tus páginas originales. Aunque Google no tiene una penalización específica por contenido duplicado, los efectos indirectos pueden perjudicar considerablemente tu visibilidad en búsquedas y tu tráfico orgánico.
Comprendiendo el contenido duplicado y su impacto en el SEO
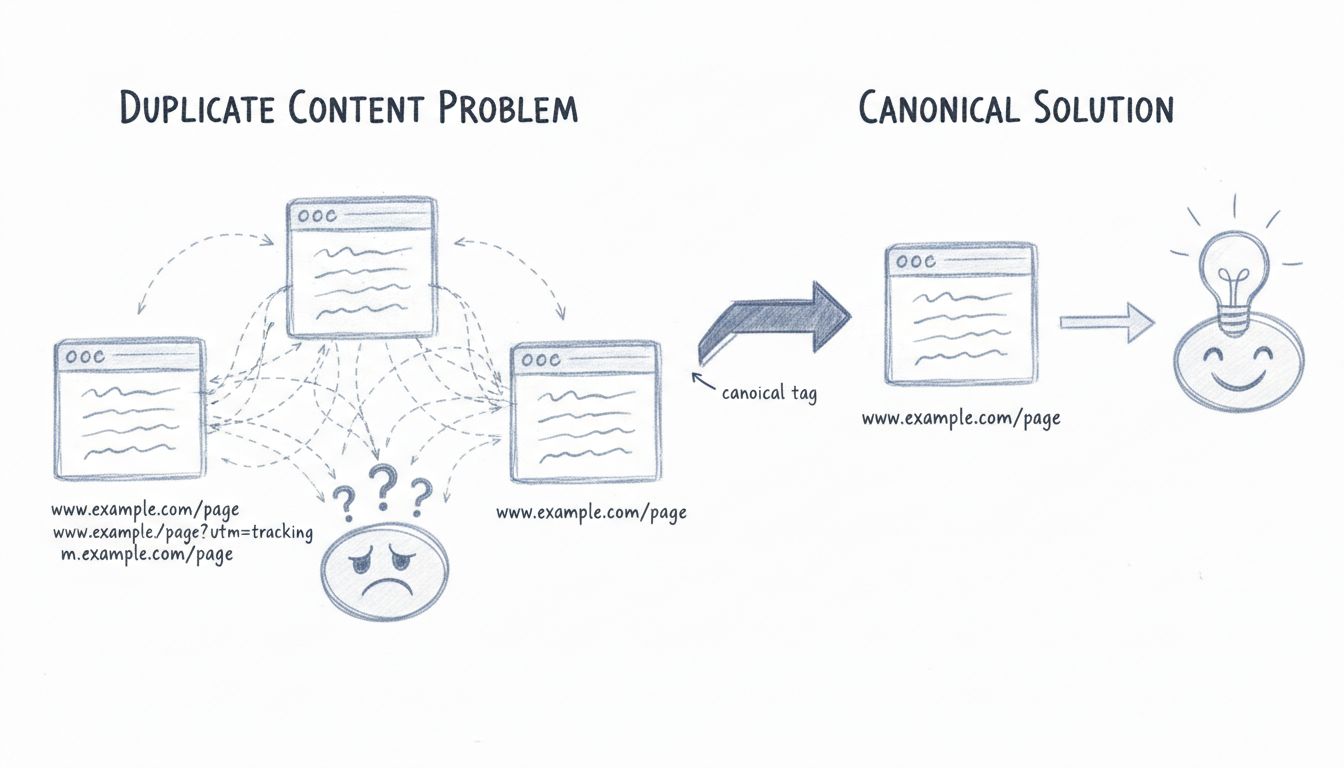
El contenido duplicado se refiere a contenido idéntico o sustancialmente similar que aparece en internet en varias URLs. Esto puede ocurrir dentro de un mismo sitio web o entre diferentes dominios. Según datos recientes, aproximadamente el 25-30% de la web consiste en contenido duplicado, lo que lo convierte en uno de los desafíos técnicos más comunes de SEO que enfrentan los propietarios de sitios hoy en día. Cuando los motores de búsqueda encuentran múltiples versiones del mismo contenido, deben decidir cuál es la fuente autorizada, qué versión indexar y cuál posicionar en los resultados de búsqueda. Este proceso de toma de decisiones genera varias complicaciones que pueden afectar negativamente la visibilidad de tu sitio web en los motores de búsqueda y el rendimiento del tráfico orgánico.
La confusión que crea el contenido duplicado para los motores de búsqueda es fundamentalmente diferente de una penalización directa. Google ha declarado explícitamente en varias ocasiones que no existe una penalización por contenido duplicado. Sin embargo, esto no significa que el contenido duplicado sea inofensivo. Los efectos indirectos del contenido duplicado pueden ser tan perjudiciales para tu rendimiento SEO como lo sería una penalización directa. Comprender estos efectos es crucial para mantener un sitio web saludable y bien optimizado que obtenga buenos resultados en las búsquedas.
Cómo el contenido duplicado confunde a los motores de búsqueda
Motores de búsqueda como Google utilizan algoritmos sofisticados para determinar qué versión del contenido duplicado debe ser indexada y posicionada. Cuando existen múltiples versiones del mismo contenido, los motores de búsqueda deben consolidar estas páginas en lo que se denomina un “clúster de duplicados”. A partir de este clúster, Google selecciona la URL que considera mejor para representar el contenido en los resultados de búsqueda. Este proceso, conocido como canonicalización, está diseñado para consolidar la autoridad de los enlaces y el poder de posicionamiento en una sola URL.
Sin embargo, este proceso automático no siempre funciona a la perfección. Los motores de búsqueda pueden seleccionar la versión incorrecta como URL canónica, lo que lleva a que aparezcan en los resultados URLs indeseadas o poco amigables. Por ejemplo, si tu sitio web tiene el mismo contenido accesible en example.com/page/ y example.com/page?utm_source=newsletter, Google podría elegir posicionar la versión con parámetros de seguimiento en lugar de la versión limpia y amigable para el usuario. Cuando los usuarios ven estas URLs poco amigables en los resultados, es menos probable que hagan clic en ellas, lo que resulta en una menor tasa de clics y una reducción del tráfico orgánico incluso si tu página está bien posicionada.
Lanza tu programa de afiliados hoy
Configura el seguimiento avanzado en minutos. No se requiere tarjeta de crédito.
El problema de la dilución de la autoridad de enlaces
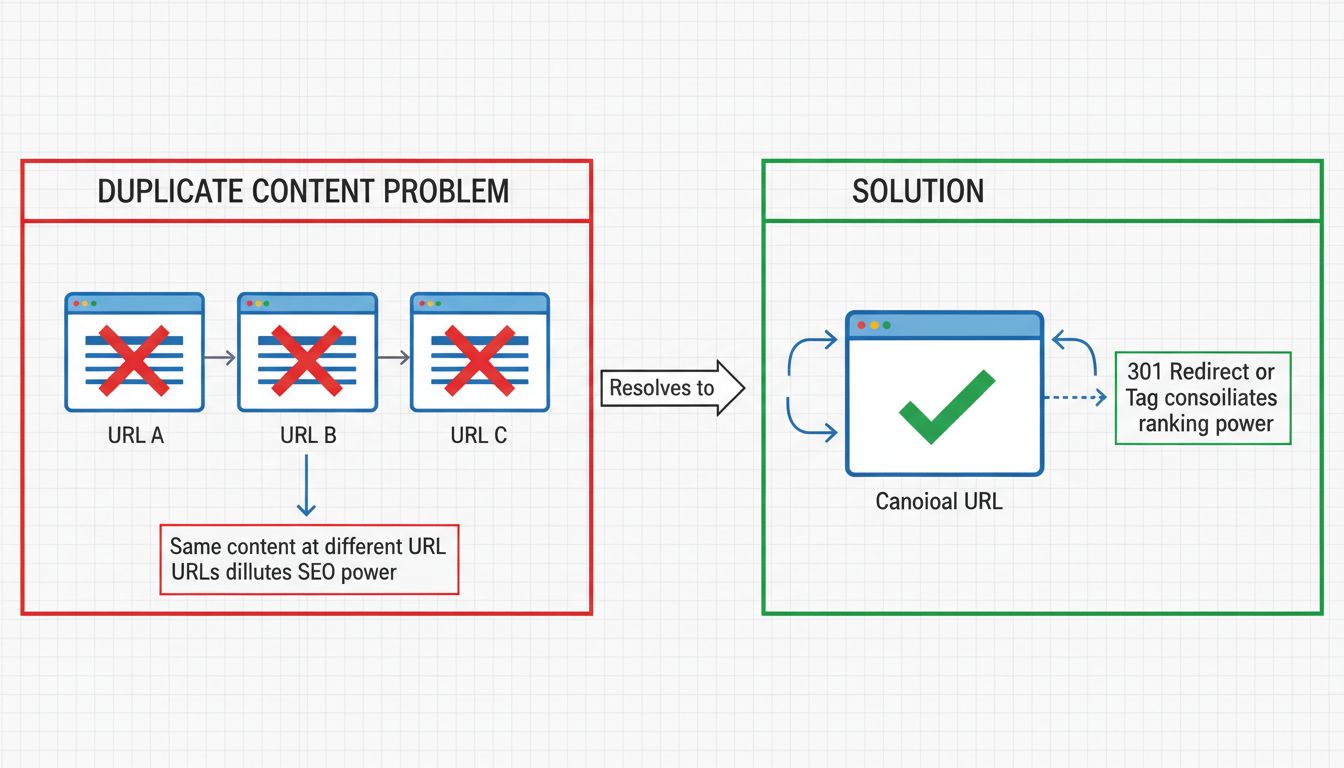
Una de las formas más significativas en que el contenido duplicado perjudica al SEO es a través de la dilución de la autoridad de enlaces. Cuando el mismo contenido existe en varias URLs, los enlaces externos pueden apuntar a diferentes versiones de ese contenido. En lugar de que toda la autoridad de enlaces se transfiera a una sola página autorizada, se distribuye entre varias URLs duplicadas. Esta fragmentación debilita la señal de autoridad general que los motores de búsqueda utilizan para determinar el posicionamiento.
Considera un ejemplo real: si tu contenido es accesible tanto en buffer.com/library/social-media-manager-checklist como en buffer.com/resources/social-media-manager-checklist, los sitios externos pueden enlazar a cualquiera de las dos versiones. Una URL puede acumular 106 dominios de referencia mientras que la otra acumula 144. Aunque el proceso de canonicalización de Google debería, en teoría, consolidar estos enlaces en una sola URL, en la práctica ambas URLs pueden seguir posicionándose por separado, lo que significa que la autoridad no se consolida completamente. Esto da como resultado dos páginas moderadamente fuertes en lugar de una página poderosa y autorizada que podría posicionarse mejor y captar más tráfico.
Desperdicio del presupuesto de rastreo y retrasos en la indexación
Los motores de búsqueda asignan un presupuesto de rastreo limitado a cada sitio web, que representa la cantidad de páginas que rastrearán e indexarán en un periodo determinado. Cuando tu sitio contiene grandes cantidades de contenido duplicado, los motores de búsqueda desperdician este valioso presupuesto rastreando y volviendo a rastrear páginas duplicadas en lugar de descubrir e indexar contenido nuevo o páginas actualizadas. Esto es especialmente problemático para sitios web con tiempos de respuesta lentos o ancho de banda limitado, ya que el límite de velocidad de rastreo de Google es mayor para sitios más receptivos.
Cuando el presupuesto de rastreo se desperdicia en duplicados, puede generar retrasos en la indexación de nuevas páginas y en la actualización de páginas existentes. Esto significa que el contenido nuevo que publicas puede tardar más en aparecer en los resultados de búsqueda y las actualizaciones de contenido pueden no reflejarse tan rápido como deberían en el índice de Google. Para sitios con mucho contenido o que publican con frecuencia, este retraso puede traducirse en oportunidades perdidas de tráfico orgánico y visibilidad en las búsquedas.
Establece el dominio preferido en Google Search Console y usa redirecciones
Barras finales
URLs con y sin barra final tratadas como páginas diferentes
Implementa redirecciones consistentes (por ejemplo, siempre usa barra final)
Versiones móviles
URLs móviles separadas (m.ejemplo.com) con contenido idéntico
Usa etiquetas rel=“alternate” o diseño responsive
Páginas AMP
Accelerated Mobile Pages crean versiones duplicadas
Canonicaliza las páginas AMP hacia las versiones no AMP
URLs para imprimir
Versiones para imprimir con el mismo contenido
Canonicaliza las versiones para imprimir hacia las originales
Páginas de etiquetas/categorías
Varias páginas de etiquetas con contenido idéntico cuando solo un artículo usa esas etiquetas
Noindex a páginas de etiquetas de bajo valor o consolida etiquetas
Paginación
Paginación de comentarios o productos genera múltiples páginas similares
Usa rel=“prev” y rel=“next” o noindexa páginas paginadas
Entornos de prueba
Sitios de desarrollo/prueba indexados por motores de búsqueda
Protege entornos de prueba con robots.txt, noindex o autenticación
Evitar que el contenido copiado te supere en los resultados
Aunque los problemas de contenido duplicado dentro de tu propio sitio son comunes, el contenido duplicado externo también puede afectar a tu SEO. Cuando otros sitios copian tu contenido o lo republican sin permiso, crean contenido duplicado en varios dominios. En casos raros, si el sitio que copia tiene mayor autoridad de dominio que el tuyo, Google podría identificar erróneamente su versión como la original y posicionarla por encima de tu contenido auténtico. Esto es especialmente problemático para sitios nuevos o pequeños que compiten contra dominios más consolidados.
Para protegerte, debes implementar etiquetas canónicas autorreferenciadas en todas tus páginas. Una etiqueta canónica autorreferenciada apunta a la propia página, indicando a los motores de búsqueda que esta es la versión original. Aunque no todos los sitios que copian tu contenido conservarán tu código HTML, aquellos que sí lo hagan verán tu etiqueta canónica y entenderán cuál es la versión original. Además, si distribuyes tu contenido intencionalmente en otros sitios, solicita siempre que incluyan un enlace canónico hacia tu contenido original. Así, aunque tu contenido aparezca en varios lugares, todo el valor SEO regresará a tu sitio.
Soluciones técnicas para corregir el contenido duplicado
Implementación de etiquetas canónicas
La etiqueta canónica es una de las soluciones más efectivas y ampliamente utilizadas para gestionar el contenido duplicado. Este elemento HTML indica a los motores de búsqueda qué versión de una página debe ser tratada como fuente autoritativa. La etiqueta canónica se coloca en la sección <head> de tu HTML y se ve así:
Al agregar esta etiqueta en las páginas duplicadas, apuntando a la versión canónica (original), los motores de búsqueda consolidan el poder de posicionamiento y la autoridad de enlaces en esa única URL. La etiqueta canónica transfiere aproximadamente la misma cantidad de autoridad de enlaces que una redirección 301, pero suele ser más fácil de implementar ya que no requiere configuración a nivel de servidor. Esto la hace especialmente útil para gestionar contenido duplicado causado por parámetros de URL, versiones móviles y páginas AMP.
Uso de redirecciones 301
Una redirección 301 es una redirección permanente que indica tanto a usuarios como a motores de búsqueda que una página se ha movido de forma definitiva a una nueva ubicación. Al implementar redirecciones 301 desde URLs duplicadas hacia la versión canónica, consolidas todo el poder de posicionamiento y la autoridad de enlaces en la URL destino. Esta suele ser la mejor solución cuando quieres eliminar completamente las URLs duplicadas de tu sitio.
Por ejemplo, si tu sitio es accesible tanto en http://example.com como en https://www.example.com, debes configurar redirecciones 301 para que todo el tráfico y los rastreadores sean dirigidos a tu versión preferida. Así aseguras que los motores de búsqueda solo indexen una versión de tu sitio, evitando problemas de contenido duplicado por completo. La redirección 301 transfiere casi el 100% de la autoridad de enlaces a la página redirigida, convirtiéndola en una excelente opción para consolidar contenido duplicado.
Etiqueta Meta Robots Noindex
La etiqueta meta robots noindex es especialmente útil para gestionar contenido duplicado que quieres que esté disponible para los usuarios pero no deseas que sea indexado por los motores de búsqueda. Al añadir <meta name="robots" content="noindex,follow"> en el <head> de una página, indicas a los motores de búsqueda que no incluyan esa página en su índice pero que sí pueden rastrear y seguir los enlaces de la página.
Esta solución es ideal para gestionar contenido duplicado proveniente de paginación, páginas de etiquetas, páginas de filtros y otras páginas generadas automáticamente que no aportan valor único. Sin embargo, es importante señalar que Google sigue rastreando estas páginas para verificar tu directiva noindex, por lo que no debes bloquearlas en tu archivo robots.txt. La etiqueta noindex es menos efectiva que las etiquetas canónicas o las redirecciones 301 en cuanto a consolidación de autoridad, pero es una excelente forma de evitar que páginas duplicadas de bajo valor saturen tus resultados de búsqueda.
Cómo detectar contenido duplicado en tu sitio web
Para identificar problemas de contenido duplicado en tu sitio web, debes realizar auditorías integrales con herramientas SEO especializadas de forma regular. Estas herramientas rastrean todo tu sitio e identifican páginas con contenido idéntico o muy similar. Al revisar los resultados, busca clústeres de páginas duplicadas sin las etiquetas canónicas adecuadas; estas se destacan como problemas que requieren atención.
Google Search Console también ofrece información valiosa sobre contenido duplicado. El Informe de Cobertura muestra qué páginas ha indexado Google y señala problemas como “Duplicada sin canonización seleccionada por el usuario” o “Duplicada, Google eligió una canónica diferente a la del usuario”. Estas advertencias indican que Google ha detectado contenido duplicado en tu sitio y puede que no lo esté gestionando como tú esperas. La herramienta de Inspección de URL en Search Console te permite comprobar cómo trata Google URLs específicas, mostrando si una página está indexada, canonizada o bloqueada para su indexación.
Mejores prácticas para prevenir el contenido duplicado
Prevenir el contenido duplicado es mucho más sencillo que corregirlo después. Comienza estableciendo estándares claros de URL para tu sitio web y mantén la coherencia en toda la arquitectura. Al crear enlaces internos, enlaza siempre a la misma versión de las URLs: no mezcles versiones con y sin www ni alternes entre usar o no barras finales. Esta coherencia ayuda a los motores de búsqueda a comprender tu estructura de URLs preferida.
Para sitios de comercio electrónico que usan navegación facetada con filtros y opciones de orden, implementa un manejo adecuado de parámetros para evitar la creación de cientos de páginas duplicadas. Usa etiquetas canónicas para consolidar vistas filtradas hacia la página base del producto, o utiliza la herramienta de manejo de parámetros en Google Search Console para indicar a Google qué parámetros deben ignorarse al rastrear tu sitio.
Si usas un sistema de gestión de contenidos como WordPress, desactiva funciones que generen automáticamente contenido duplicado, como páginas dedicadas para adjuntos de imágenes y comentarios paginados. La mayoría de los CMS modernos tienen configuraciones para controlar estos comportamientos. Además, protege tus entornos de prueba y desarrollo para que no sean indexados mediante directivas robots.txt, etiquetas meta noindex o autenticación HTTP, evitando así que los motores de búsqueda rastreen estas versiones duplicadas de tu sitio.
Conclusión sobre el contenido duplicado y el SEO
Aunque Google no tiene una penalización específica por contenido duplicado, los efectos indirectos de este problema pueden perjudicar significativamente el rendimiento SEO de tu sitio. El contenido duplicado confunde a los motores de búsqueda sobre qué versión posicionar, diluye la autoridad de enlaces entre varias URLs, desperdicia el presupuesto de rastreo y puede permitir que contenido copiado supere a tus páginas originales. Al implementar etiquetas canónicas, redirecciones 301 y una estructura de URLs adecuada, puedes prevenir y solucionar los problemas de contenido duplicado antes de que dañen tu visibilidad en las búsquedas.
La clave para mantener un sitio saludable es ser proactivo en la gestión del contenido duplicado. Audita tu sitio regularmente en busca de problemas, aplica estrategias de canonicalización adecuadas y mantén estándares de URL coherentes en toda tu web. Al tomar estas medidas, aseguras que los motores de búsqueda puedan identificar fácilmente tu contenido original, consolidar la autoridad de enlaces en tus URLs preferidas y rastrear e indexar tu sitio de forma eficiente. Esto se traduce en mejores posiciones, más tráfico orgánico y un rendimiento SEO más sólido para tu sitio web.
Optimiza tu sitio de afiliados con PostAffiliatePro
Gestiona múltiples programas de afiliados y evita problemas de contenido duplicado con las funciones avanzadas de seguimiento y gestión de contenidos de PostAffiliatePro. Asegura que tus esfuerzos de marketing de afiliados generen el máximo valor SEO.
Aprende cómo comprobar si existe contenido duplicado usando herramientas como Copyscape, Siteliner y Google Search Console. Descubre métodos manuales, detección...
El contenido duplicado se refiere a contenido idéntico o similar que aparece en varias URLs, ya sea dentro de un solo sitio web o en diferentes sitios. Aunque n...
6 min de lectura
SEO
Content
+3
¡Estarás en buenas manos!
Únete a nuestra comunidad de clientes satisfechos y brinda excelente soporte al cliente con Post Affiliate Pro.