
¿Qué significa la indexación en SEO?
Aprende qué significa la indexación en SEO, cómo funciona y por qué es fundamental para la visibilidad de tu sitio web en los motores de búsqueda. Descubre las ...
13 min de lectura
Descubre qué significa la indexación de páginas, por qué Google no indexa algunas páginas y cómo solucionar problemas de indexación. Conoce soluciones técnicas y mejores prácticas para 2025.
Cuando una página no está indexada, significa que el motor de búsqueda no la ha añadido a su base de datos, por lo que no aparecerá en los resultados de búsqueda. Esto puede ocurrir por problemas técnicos como etiquetas noindex o bloqueos en robots.txt, errores de rastreo, contenido duplicado, baja calidad o simplemente porque la página aún no ha sido descubierta.
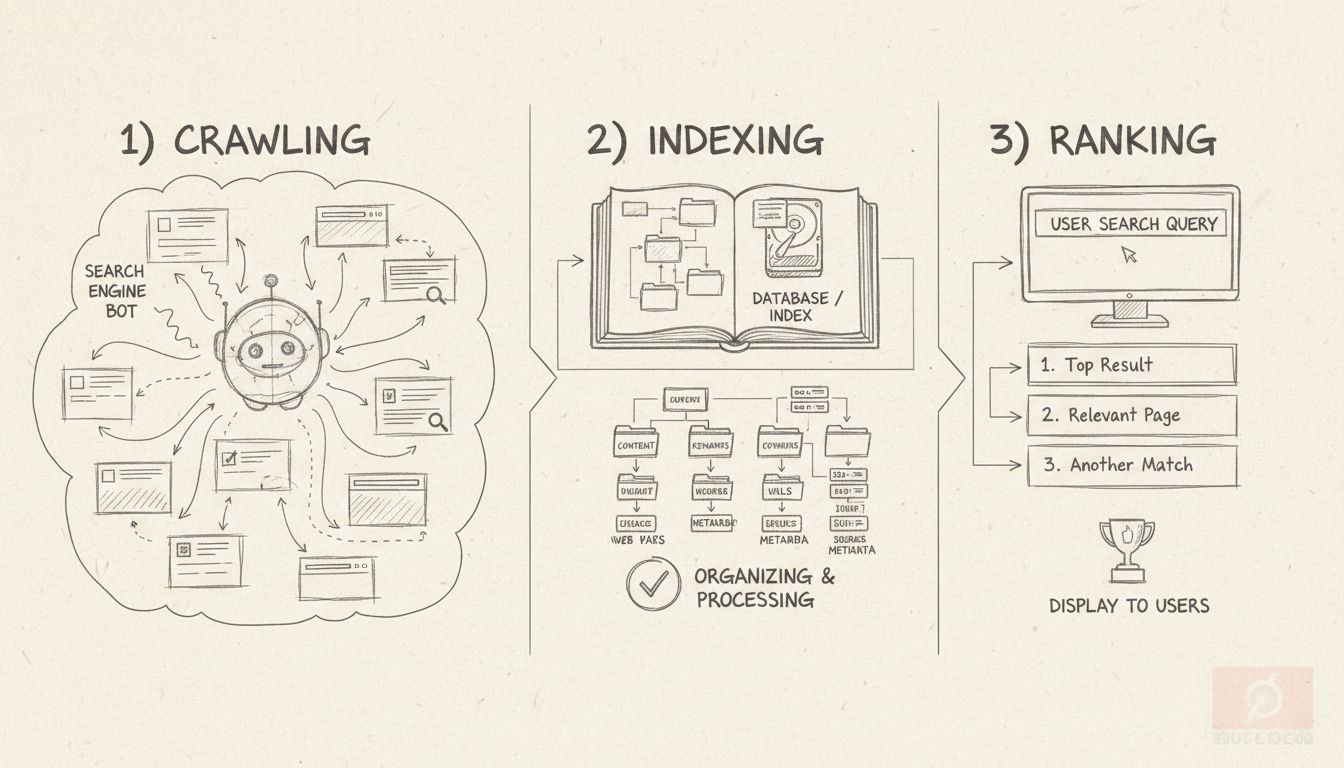
Cuando una página “no está indexada”, significa que el motor de búsqueda de Google no la ha agregado a su base de datos, por lo que será invisible en los resultados de búsqueda. Esto es fundamentalmente diferente de una página que existe pero simplemente no posiciona bien para determinadas palabras clave. Entender la diferencia entre indexación y posicionamiento es crucial para cualquier persona que gestione contenido en línea o campañas de marketing de afiliados. La indexación es el paso previo que debe ocurrir antes de que una página pueda siquiera aspirar a aparecer en los resultados de búsqueda. Sin indexación, tu contenido es esencialmente invisible para los motores de búsqueda y para los visitantes potenciales que confían en Google para encontrar información. El proceso de indexación implica tres etapas críticas: rastreo (cuando Googlebot visita tu página), indexación (cuando la página se añade a la base de datos de Google) y posicionamiento (cuando la página aparece en los resultados de búsqueda para consultas relevantes).
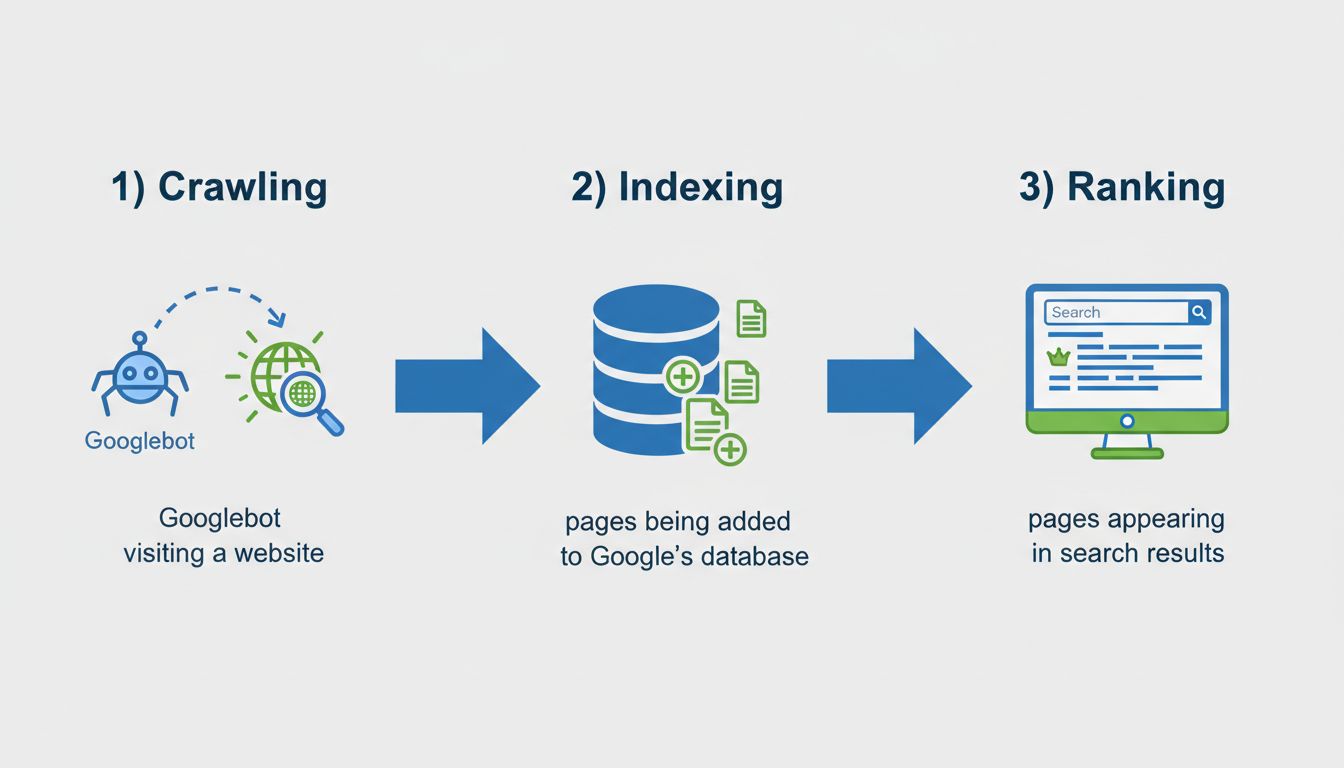
Existen numerosas razones por las que una página puede no estar indexada, y generalmente se dividen en tres categorías principales: problemas técnicos, problemas de calidad de contenido y problemas de descubrimiento. Comprender cada categoría te ayudará a diagnosticar y solucionar problemas de indexación de forma más efectiva. Las barreras técnicas más comunes incluyen etiquetas meta noindex, restricciones en robots.txt, conflictos con etiquetas canónicas y errores de servidor. Los problemas relacionados con el contenido suelen involucrar contenido escaso o duplicado, baja calidad o contenido que no coincide con la intención de búsqueda del usuario. Los problemas de descubrimiento ocurren cuando Google simplemente no ha encontrado tu página aún debido a la falta de enlaces internos, ausencia en el sitemap o porque la página es muy nueva.
Etiquetas Meta Noindex y Bloqueos en Robots.txt
Uno de los culpables más frecuentes detrás de páginas no indexadas es la presencia de una etiqueta meta noindex. Esta directiva HTML indica explícitamente a los motores de búsqueda que no indexen una página, incluso si pueden rastrearla correctamente. La etiqueta aparece en el código fuente de la página como <meta name="robots" content="noindex">. A veces estas etiquetas se añaden por accidente durante el desarrollo o por plugins SEO mal configurados. Para comprobar si tu página tiene una etiqueta noindex, haz clic derecho en la página, selecciona “Ver código fuente” y busca “noindex”. También puedes usar la Herramienta de Inspección de URL de Google Search Console, que indicará claramente si una página está bloqueada por una etiqueta noindex.
El archivo robots.txt es otra barrera técnica crítica. Este archivo controla qué partes de tu sitio web puede rastrear Googlebot. Si tus páginas importantes están bloqueadas en robots.txt con una directiva “Disallow”, Google no podrá rastrearlas y, por lo tanto, no las indexará. Puedes revisar tu archivo robots.txt visitando tudominio.com/robots.txt en tu navegador. Busca líneas que comiencen con “Disallow” y verifica que secciones importantes como /blog/ o /productos/ no estén bloqueadas por accidente.
Mala configuración de etiquetas canónicas
Las etiquetas canónicas le indican a Google qué versión de una página debe indexar cuando existen duplicados. Si una etiqueta canónica apunta a la URL incorrecta—como a tu página de inicio o a una página completamente diferente—Google podría ignorar la página que quieres indexar. Idealmente, cada página debe tener una etiqueta canónica autorreferente que apunte a sí misma. Puedes comprobarlo viendo el código fuente de la página y buscando link rel="canonical". Si la URL de la etiqueta canónica no coincide con la URL actual de tu página, ahí está el problema.
Errores de servidor y códigos de estado HTTP
Cuando Googlebot intenta rastrear una página y encuentra errores de servidor (códigos de estado 5xx) o errores de página no encontrada (códigos de estado 404), lo interpreta como una señal de que la página no está disponible o no funciona. Si estos errores persisten con el tiempo, Google puede eliminar la página de su índice por completo. Puedes revisar los errores de rastreo de tu sitio en Google Search Console, en el informe de “Cobertura”, que muestra páginas con códigos de estado HTTP problemáticos.
Contenido escaso y de baja calidad
Google da cada vez más prioridad a la calidad y relevancia del contenido. Las páginas con contenido escaso—es decir, que carecen de suficiente profundidad, detalle o valor—suelen ser excluidas del índice. Esto incluye páginas con muy pocas palabras, información genérica o contenido que no responde adecuadamente a las consultas de los usuarios. Los algoritmos de Google evalúan si el contenido aporta un valor genuino a los usuarios. Si una página contiene información desactualizada, carece de ideas originales o simplemente repite información disponible en otros lugares, Google puede determinar que no merece ser indexada.
Problemas de contenido duplicado
Cuando varias páginas de tu sitio contienen contenido idéntico o casi idéntico, Google suele indexar solo una versión y marca las demás como duplicados. Esto es común con descripciones de productos copiadas de los fabricantes, entradas de blog con mínimas variaciones o páginas de servicios repetidas para diferentes ubicaciones. El contenido duplicado también desperdicia tu presupuesto de rastreo, ya que Googlebot tiene que invertir recursos en identificar que las páginas son duplicadas en lugar de rastrear contenido nuevo y único.
Desajuste con la intención de búsqueda
Las páginas que no se alinean con la intención de búsqueda de los usuarios suelen ser excluidas de la indexación. Por ejemplo, si creas una página sobre “herramientas SEO” pero en realidad es una entrada de blog y no una comparativa de herramientas (que es lo que la mayoría de los usuarios espera), Google puede determinar que la página no es relevante para esa consulta y no la indexará. Es esencial comprender la intención de búsqueda analizando los resultados mejor posicionados antes de crear contenido.
Páginas huérfanas y enlazado interno
Las páginas que no tienen enlaces internos que apunten a ellas se llaman “páginas huérfanas”. Si una página no está enlazada desde ningún lugar de tu sitio y tampoco está en tu sitemap, es posible que Google nunca la descubra. Incluso si Google la encuentra, la falta de enlaces internos indica que la página no es importante, lo que puede resultar en que no se indexe. Los enlaces internos sirven como caminos para que Googlebot descubra contenido y también transmiten autoridad y señales de relevancia.
Ausencia en el sitemap
Un sitemap es un archivo que enumera las páginas importantes de tu sitio web y ayuda a Google a descubrirlas y priorizarlas para el rastreo. Si una página no está incluida en tu sitemap, será más difícil para Google encontrarla, especialmente si también carece de enlaces internos. Aunque las páginas pueden ser indexadas sin estar en el sitemap, su inclusión mejora significativamente la capacidad de descubrimiento.
Limitaciones del presupuesto de rastreo
Los sitios web grandes tienen un “presupuesto de rastreo” limitado: el número de páginas que Google rastreará en un periodo determinado. Si tu sitio tiene muchas páginas de baja calidad, tiempos de carga lentos o excesivo contenido duplicado, Google puede asignar menos recursos para rastrearlo. Esto significa que algunas páginas pueden no ser rastreadas e indexadas de manera oportuna, o incluso nunca.
Configura el seguimiento avanzado en minutos. No se requiere tarjeta de crédito.
Google Search Console es la herramienta principal para diagnosticar por qué las páginas no están indexadas. La plataforma proporciona informes detallados que muestran exactamente qué páginas están indexadas y por qué otras no lo están. Para acceder a esta información, entra en tu propiedad de Search Console, haz clic en “Indexación” en el menú de la izquierda y selecciona “Páginas”. Este informe muestra tus páginas indexadas y un desglose de las páginas no indexadas según la razón.
| Tipo de problema | Estado en GSC | Qué significa | Solución |
|---|---|---|---|
| Etiqueta Noindex | Excluida por etiqueta ’noindex' | La página tiene directiva noindex | Eliminar la etiqueta noindex de la página |
| Bloqueo en Robots.txt | Bloqueada por robots.txt | La página está denegada en robots.txt | Actualizar robots.txt para permitir el rastreo |
| Contenido duplicado | Duplicado sin canónica seleccionada por el usuario | Existen varias páginas similares | Añadir etiquetas canónicas o consolidar contenido |
| Baja calidad | Descubierta – actualmente no indexada | Página considerada de bajo valor | Mejorar la profundidad y calidad del contenido |
| No descubierta | Descubierta – actualmente no indexada | Página aún no rastreada | Añadir enlaces internos y enviar el sitemap |
| Error de servidor | Anomalía de rastreo | El servidor devolvió un error | Corregir problemas de servidor y reenviar la página |
La Herramienta de Inspección de URL es otra función poderosa. Simplemente pega una URL específica en la barra de búsqueda en la parte superior de Search Console y Google te mostrará si esa página está indexada, cuándo fue rastreada por última vez y cualquier problema que impida la indexación. Si una página no está indexada, la herramienta explicará el motivo y, a menudo, te ofrecerá un botón de “Solicitar indexación” para pedir a Google que rastree la página de nuevo.
Eliminar barreras técnicas
Comienza abordando los problemas técnicos. Si tu página tiene una etiqueta noindex y quieres que se indexe, elimina la etiqueta del HTML de la página. En WordPress, esto normalmente se hace desde tu plugin SEO (Yoast, Rank Math, All in One SEO) desmarcando la opción “Permitir que los motores de búsqueda indexen esta página”. Si la página está bloqueada en robots.txt, actualiza tu archivo robots.txt para permitir el rastreo de esa sección. Para problemas con etiquetas canónicas, asegúrate de que cada página tenga una etiqueta canónica autorreferente que apunte a sí misma.
Mejorar la calidad del contenido
Si tu página aparece como “Descubierta – actualmente no indexada” o “Rastreada – actualmente no indexada”, probablemente el problema sea la calidad del contenido. Amplía tu contenido para ofrecer información más completa, añade ideas o datos originales, asegúrate de que responde a la intención de búsqueda y elimina cualquier contenido duplicado. Verifica que tu página realmente responda a las preguntas que los usuarios se hacen al buscar términos relacionados.
Mejorar el enlazado interno
Añade enlaces internos desde páginas relevantes de tu sitio hacia la página no indexada. Estos enlaces deben utilizar texto ancla descriptivo y ubicarse de forma natural dentro del contenido. Procura tener entre 2 y 5 enlaces internos por página. Además, asegúrate de que la página esté incluida en tu sitemap XML y que el sitemap haya sido enviado a Google Search Console.
Solicitar indexación
Después de realizar las correcciones, utiliza la Herramienta de Inspección de URL en Google Search Console para solicitar la indexación. Google volverá a rastrear la página y evaluará si debe ser indexada. Aunque no hay un plazo garantizado, normalmente las páginas se vuelven a rastrear en unos días o un par de semanas.
Sé el primero en conocer las nuevas funciones y actualizaciones del producto.
Mantener una buena salud de indexación requiere atención continua. Audita tu sitio regularmente usando Google Search Console para vigilar el estado de indexación. Asegúrate de que tu archivo robots.txt esté bien configurado y no bloquee contenido importante por accidente. Implementa etiquetas canónicas adecuadas en todo tu sitio, especialmente si tienes múltiples versiones de contenido similar. Mantén prácticas constantes de enlazado interno, conectando contenidos relacionados para que Google comprenda mejor la estructura de tu sitio. Finalmente, enfócate en crear contenido original y de alta calidad que aporte valor real a tu audiencia. Esta es la estrategia más eficaz a largo plazo para asegurar que tus páginas sean indexadas y posicionadas.
Haz un seguimiento y gestiona tus campañas de afiliados de manera efectiva con el avanzado sistema de seguimiento y análisis de PostAffiliatePro. Asegúrate de que tu contenido llegue a la audiencia correcta y maximiza tus ingresos de afiliado con nuestra plataforma líder en la industria.
Aprende qué significa la indexación en SEO, cómo funciona y por qué es fundamental para la visibilidad de tu sitio web en los motores de búsqueda. Descubre las ...
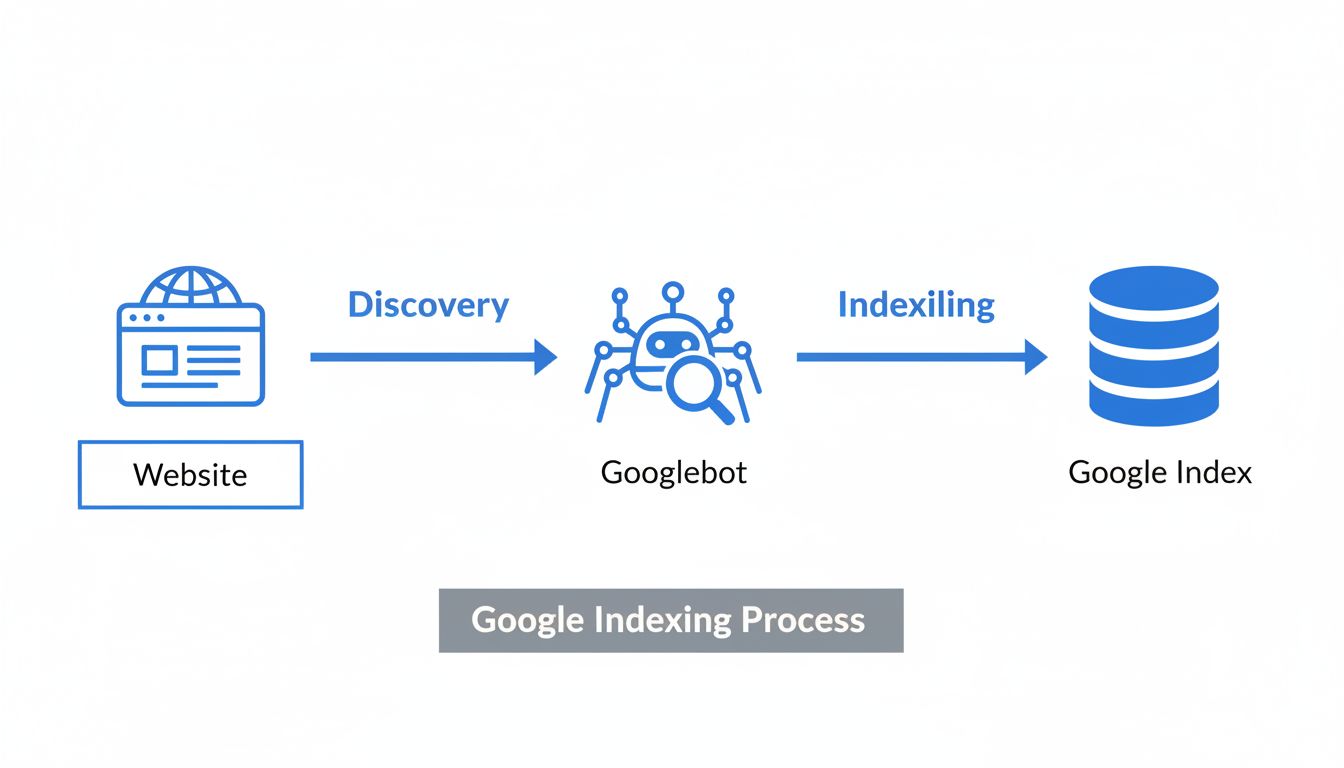
Aprende 7 métodos comprobados para verificar si tu sitio web está indexado por Google. Utiliza Google Search Console, operadores de búsqueda, herramientas de in...
La indexación es un proceso mediante el cual los rastreadores encuentran una página web determinada. Se detectan las señales clave y todos los datos se almacena...
Únete a nuestra comunidad de clientes satisfechos y brinda excelente soporte al cliente con Post Affiliate Pro.
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.