Descubre por qué las páginas fantasma perjudican el SEO, cómo desperdician el presupuesto de rastreo, generan problemas de contenido duplicado y conoce estrategias efectivas para eliminarlas de tu sitio web.
¿Son malas las páginas fantasma para el SEO?
Sí, las páginas fantasma generalmente son perjudiciales para el SEO. Desperdician el presupuesto de rastreo, generan problemas de contenido duplicado, diluyen la autoridad de los enlaces y afectan negativamente la experiencia del usuario. Los motores de búsqueda pueden penalizar los sitios con un exceso de páginas fantasma, lo que lleva a un descenso en los rankings y a una menor visibilidad orgánica.
Comprendiendo las páginas fantasma y su impacto en el SEO
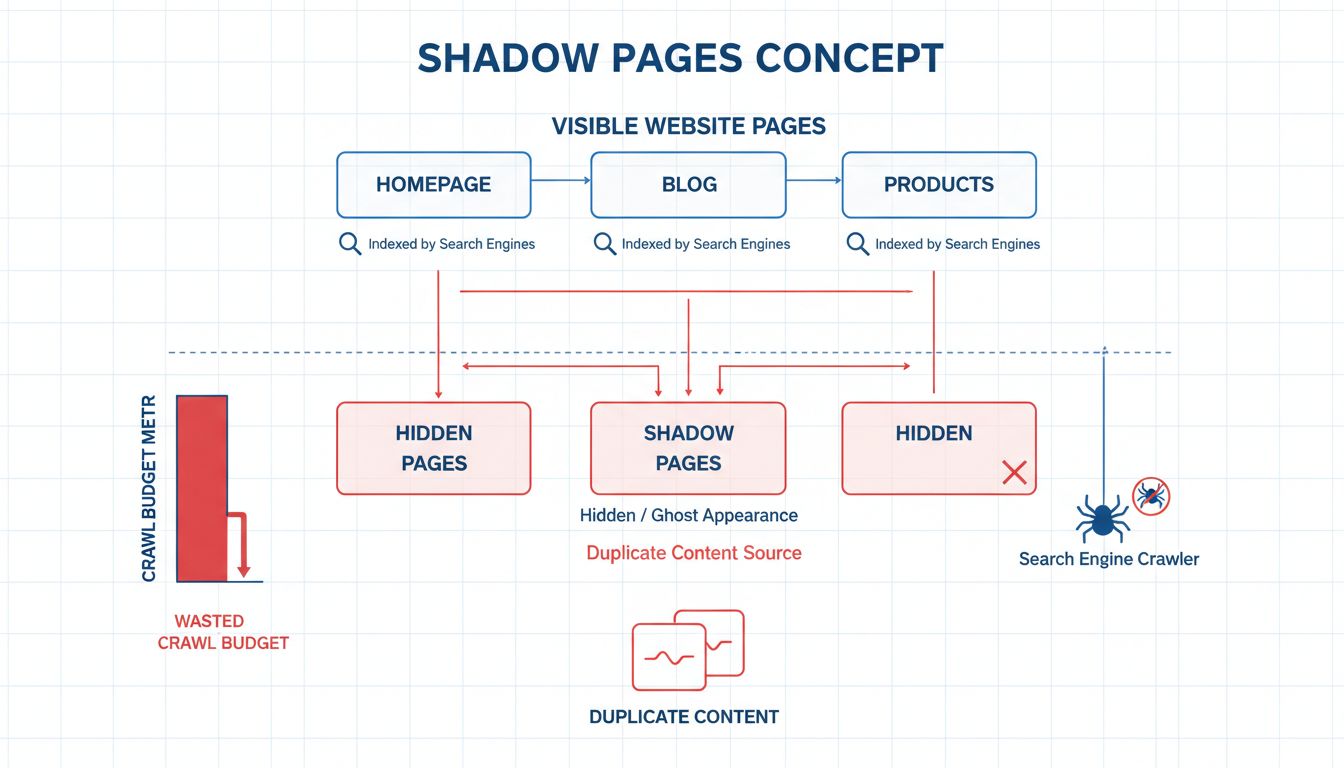
Las páginas fantasma, también conocidas como páginas ocultas, son páginas web que existen en tu sitio pero permanecen ocultas para los usuarios y, a menudo, no son indexadas por los motores de búsqueda. Estas páginas suelen surgir de manera involuntaria debido a una arquitectura de sitio deficiente, generación dinámica de contenido sin enlaces adecuados o una gestión inapropiada de redirecciones. A diferencia de las páginas ocultas de manera intencionada para fines específicos, las páginas fantasma representan un problema estructural que los motores de búsqueda tienen dificultades para categorizar e indexar correctamente. El problema fundamental es que estas páginas consumen valiosos recursos sin aportar de manera significativa al rendimiento SEO de tu sitio ni a la experiencia del usuario.
La presencia de páginas fantasma genera una serie de problemas en cascada que se agravan con el tiempo. Cuando los rastreadores de los motores de búsqueda encuentran estas páginas, deben decidir si rastrearlas e indexarlas, lo que desvía la atención de contenido más relevante. Esta ineficiencia se vuelve cada vez más problemática a medida que tu sitio web crece, ya que los motores de búsqueda asignan un presupuesto de rastreo limitado a cada dominio. Cada segundo dedicado a rastrear páginas fantasma es un segundo que no se invierte en páginas realmente importantes para los objetivos de tu negocio y las métricas de participación de los usuarios.
Cómo dañan las páginas fantasma el rendimiento SEO
Desperdicio de presupuesto de rastreo y problemas de indexación
Los motores de búsqueda como Google asignan un presupuesto de rastreo específico a cada sitio web en función de su autoridad, tamaño y frecuencia de actualización. Este presupuesto representa la cantidad máxima de páginas que Googlebot rastreará durante un periodo determinado. Cuando las páginas fantasma consumen parte de este presupuesto limitado, menos páginas importantes son rastreadas e indexadas oportunamente. Para los sitios grandes con miles de páginas, esto se convierte en un problema crítico que afecta directamente la velocidad con la que el nuevo contenido es descubierto y posicionado.
El problema del presupuesto de rastreo se agrava especialmente cuando las páginas fantasma se generan dinámicamente con IDs de sesión, parámetros de seguimiento u otras variaciones de URL. Cada variación aparece como una página única para los motores de búsqueda, multiplicando exponencialmente el desperdicio del presupuesto de rastreo. Una sola página de producto con múltiples combinaciones de parámetros podría generar docenas de páginas fantasma, cada una consumiendo presupuesto que podría haberse utilizado para contenido realmente crucial para el negocio. Esta ineficiencia significa que tus entradas de blog, páginas de producto y descripciones de servicios pueden tardar semanas o meses en ser indexadas por completo en lugar de días.
Problemas de contenido duplicado y canibalización de palabras clave
Las páginas fantasma suelen contener contenido idéntico o muy similar al de páginas ya indexadas en tu sitio. Cuando los motores de búsqueda encuentran varias versiones del mismo contenido, enfrentan un dilema: ¿qué versión debería posicionarse para la palabra clave objetivo? Esta confusión conduce a la canibalización de palabras clave, donde tus propias páginas compiten entre sí en los resultados de búsqueda. En lugar de consolidar el poder de posicionamiento en una sola página autorizada, tu valor SEO se diluye en varias páginas, lo que resulta en un rendimiento general más débil.
El problema del contenido duplicado va más allá de la simple confusión en el posicionamiento. Los algoritmos de Google están diseñados para identificar y penalizar sitios que parecen crear contenido duplicado de manera deliberada para manipular los resultados. Aunque las páginas fantasma suelen ser accidentales, los sistemas de Google no siempre pueden distinguir entre duplicados accidentales y spam intencionado. Esto significa que tu sitio corre el riesgo de recibir penalizaciones manuales o algorítmicas que podrían reducir significativamente tu visibilidad en todos los resultados de búsqueda, no solo en las páginas duplicadas.
Dilución de la autoridad de enlaces y pérdida de autoridad
Los backlinks son uno de los factores de posicionamiento más importantes en el algoritmo de Google y representan votos de confianza de otros sitios web. Cuando las páginas fantasma acumulan backlinks—ya sea a través de enlaces internos o referencias externas—esa autoridad de enlaces se distribuye entre varias páginas en lugar de concentrarse en tu contenido principal. Esta dilución debilita la autoridad de tus páginas más importantes y reduce su capacidad para posicionarse en palabras clave competitivas.
El enlazado interno se vuelve especialmente problemático con las páginas fantasma. Si la arquitectura de tu sitio genera múltiples URLs para el mismo contenido y algunas de estas URLs reciben enlaces internos mientras que otras no, básicamente estás dividiendo tu autoridad de enlaces. Una página que debería recibir diez enlaces internos podría recibir solo cinco, mientras que la versión fantasma recibe los otros cinco. Esta fragmentación impide que cualquier página acumule suficiente autoridad para posicionarse eficazmente en palabras clave de alto valor.
Lanza tu programa de afiliados hoy
Configura el seguimiento avanzado en minutos. No se requiere tarjeta de crédito.
Comprender cómo se forman las páginas fantasma es esencial para prevenirlas. Los parámetros de URL dinámicos representan una de las causas más comunes, donde IDs de sesión, códigos de seguimiento o preferencias de usuario crean URLs únicas para contenido idéntico. Los sitios de comercio electrónico suelen enfrentar este problema cuando los filtros de productos, opciones de ordenamiento o preferencias de vista generan nuevas URLs. Los sistemas de gestión de contenidos a veces crean páginas fantasma mediante parámetros de paginación, versiones para imprimir o URLs específicas para móviles que no están correctamente consolidadas con etiquetas canónicas.
La implementación incorrecta de redirecciones también genera páginas fantasma. Cuando los sitios migran contenido, cambian estructuras de URL o consolidan páginas, las URLs antiguas deben redirigirse a las nuevas mediante redirecciones 301. Si estas redirecciones no se configuran correctamente, los motores de búsqueda pueden indexar tanto las URLs antiguas como las nuevas, creando problemas de contenido duplicado. De forma similar, los sitios que no implementan adecuadamente las redirecciones HTTPS o no consolidan las versiones con y sin www generan múltiples páginas fantasma que compiten por el posicionamiento.
Estrategias comprobadas para eliminar páginas fantasma
Implementación efectiva de etiquetas canónicas
Las etiquetas canónicas indican a los motores de búsqueda qué versión de una página debe considerarse la versión principal cuando varias URLs contienen contenido similar o idéntico. Al agregar una etiqueta rel=“canonical” a las páginas fantasma, consolidas las señales de posicionamiento y evitas que los motores de búsqueda desperdicien presupuesto de rastreo en versiones duplicadas. La etiqueta canónica debe apuntar a la versión principal de la página que deseas posicionar en los resultados de búsqueda.
Una correcta implementación canónica requiere una planificación cuidadosa. Para sitios de comercio electrónico con filtros de productos, la etiqueta canónica en los resultados filtrados debe apuntar a la página base del producto. Para contenido paginado, cada página debe tener una etiqueta canónica autorreferencial, o puedes utilizar las etiquetas rel=“next” y rel=“prev” para indicar la relación entre páginas. La clave es asegurarse de que cada página fantasma indique claramente qué página debe recibir el crédito de posicionamiento.
Uso de directivas noindex para páginas no esenciales
La metaetiqueta noindex impide que los motores de búsqueda indexen páginas específicas, aunque sigan siendo rastreables y accesibles para los usuarios. Este enfoque funciona bien para páginas que tienen un propósito interno pero que no deben aparecer en los resultados de búsqueda, como páginas de agradecimiento, páginas de inicio de sesión o resultados de búsqueda internos. Al aplicar noindex a las páginas fantasma que no aportan valor a los usuarios de búsqueda, evitas que consuman presupuesto de rastreo y compitan con tu contenido principal.
Implementar noindex requiere una consideración cuidadosa para evitar bloquear accidentalmente páginas importantes. Debes auditar tu sitio minuciosamente para identificar qué páginas realmente no necesitan ser indexadas. Los candidatos comunes incluyen páginas de contenido duplicado, páginas con poco contenido y páginas creadas para navegación interna o fines de seguimiento. Una vez identificadas, agrega la etiqueta noindex a estas páginas y monitorea Google Search Console para confirmar que ya no aparecen en los resultados de búsqueda.
Reestructuración de la arquitectura del sitio y enlazado interno
La solución más efectiva a largo plazo implica reestructurar la arquitectura de tu sitio para eliminar las condiciones que generan páginas fantasma. Esto significa consolidar contenido duplicado en páginas únicas y autorizadas, implementar estructuras de URL adecuadas que no generen variaciones innecesarias y asegurarte de que todas las páginas importantes estén correctamente enlazadas desde la navegación y el contenido de tu sitio.
Para contenido dinámico, implementa la reescritura de URLs para crear URLs limpias y estáticas que no expongan IDs de sesión o parámetros de seguimiento. Utiliza estructuras de URL consistentes en todo tu sitio y asegúrate de que todas las variaciones de una página (móvil, escritorio, versión para imprimir) utilicen la misma URL mediante diseño responsivo o negociación de contenido, en lugar de URLs separadas. Este enfoque no solo elimina las páginas fantasma, sino que también mejora la experiencia del usuario y facilita el rastreo e indexación de tu sitio.
Únete a nuestro boletín
Sé el primero en conocer las nuevas funciones y actualizaciones del producto.
Monitoreo y auditoría de páginas fantasma
Herramienta
Propósito
Características clave
Google Search Console
Monitoreo oficial de indexación
Muestra páginas indexadas vs. excluidas, errores de rastreo, problemas de cobertura
Screaming Frog
Auditoría técnica de SEO
Rastrea todo el sitio, identifica contenido duplicado, encuentra cadenas de redirección
Ahrefs
Análisis SEO integral
Análisis de backlinks, estimación de presupuesto de rastreo, detección de contenido duplicado
Semrush
Análisis competitivo
Funciones de auditoría de sitio, problemas técnicos de SEO, estado de indexación de páginas
Moz Pro
Conjunto de herramientas SEO
Diagnóstico de rastreo, identificación de contenido duplicado, seguimiento de posiciones
Las auditorías regulares del sitio son esenciales para identificar y eliminar páginas fantasma antes de que dañen tu rendimiento SEO. Google Search Console proporciona los datos más confiables sobre qué páginas ha descubierto e indexado Google. El informe de Cobertura muestra las páginas excluidas y los motivos de la exclusión, ayudándote a identificar páginas fantasma que los motores de búsqueda han decidido no indexar. La sección Excluidas suele revelar páginas fantasma creadas por parámetros de URL, paginación o problemas de redirección.
Screaming Frog ofrece un rastreo más completo de todo tu sitio, simulando cómo los motores de búsqueda ven tu web. Esta herramienta puede identificar contenido duplicado, cadenas de redirección, etiquetas canónicas faltantes y otros problemas técnicos que generan páginas fantasma. Al realizar auditorías regulares con Screaming Frog, puedes detectar problemas de páginas fantasma antes de que afecten significativamente tu SEO. La capacidad de la herramienta para identificar páginas con contenido similar te ayuda a consolidar duplicados y mejorar la estructura de tu sitio.
Mejores prácticas para prevenir páginas fantasma
Implementar buenas prácticas desde el principio previene que las páginas fantasma se conviertan en un problema. Utiliza siempre etiquetas canónicas en páginas con contenido similar, especialmente en sitios de comercio electrónico con resultados filtrados o contenido paginado. Asegúrate de que tu archivo robots.txt no bloquee accidentalmente páginas importantes mientras permite el rastreo de páginas fantasma. Configura tu sitemap.xml para incluir solo las páginas que quieres que se indexen, excluyendo páginas fantasma y contenido poco relevante.
Establece pautas claras de estructura de URL para tu equipo de desarrollo. Evita el uso de IDs de sesión, parámetros de seguimiento o indicadores de preferencia de usuario en las URLs. En su lugar, implementa estas funciones mediante cookies o sesiones del lado del servidor que no generen nuevas URLs. Para contenido dinámico, utiliza la reescritura de URLs para crear direcciones limpias y consistentes que los motores de búsqueda puedan entender e indexar fácilmente.
Implementa redirecciones 301 correctas siempre que cambies estructuras de URL o consolides páginas. Monitorea las cadenas de redirección para asegurarte de que no excedan tres saltos, ya que las redirecciones excesivas desperdician presupuesto de rastreo y pueden causar problemas de indexación. Prueba todas las redirecciones regularmente para confirmar que funcionan correctamente y apuntan a las páginas de destino adecuadas.
Conclusión
Las páginas fantasma representan un desafío importante para el SEO que puede perjudicar la visibilidad de tu sitio web y su potencial de tráfico orgánico. Al desperdiciar presupuesto de rastreo, crear problemas de contenido duplicado y diluir la autoridad de enlaces, las páginas fantasma impiden que tu contenido más relevante reciba la atención que merece de los motores de búsqueda. La buena noticia es que las páginas fantasma son en gran medida prevenibles mediante una arquitectura de sitio adecuada, la implementación de etiquetas canónicas y auditorías técnicas periódicas.
Tomar medidas para eliminar las páginas fantasma debe ser una prioridad en tu estrategia SEO para 2025. Comienza auditando tu sitio con Google Search Console y Screaming Frog para identificar páginas fantasma existentes. Implementa etiquetas canónicas en contenido duplicado, usa directivas noindex en páginas no esenciales y reestructura la arquitectura de tu sitio para evitar que se generen nuevas páginas fantasma. Al abordar este problema técnico de SEO, mejorarás la eficiencia de rastreo, consolidarás tu poder de posicionamiento y, en última instancia, lograrás una mejor visibilidad y tráfico orgánico para tu negocio.
Optimiza el rendimiento SEO de tu sitio web con PostAffiliatePro
Las páginas fantasma y los problemas técnicos de SEO pueden afectar significativamente el desempeño de tu marketing de afiliados. PostAffiliatePro ofrece seguimiento y análisis integral para ayudarte a identificar y resolver problemas SEO que afectan la visibilidad y conversiones de tu programa de afiliados. Monitorea tus páginas de afiliados, rastrea métricas de rendimiento y asegúrate de que todo tu contenido esté correctamente indexado y optimizado.
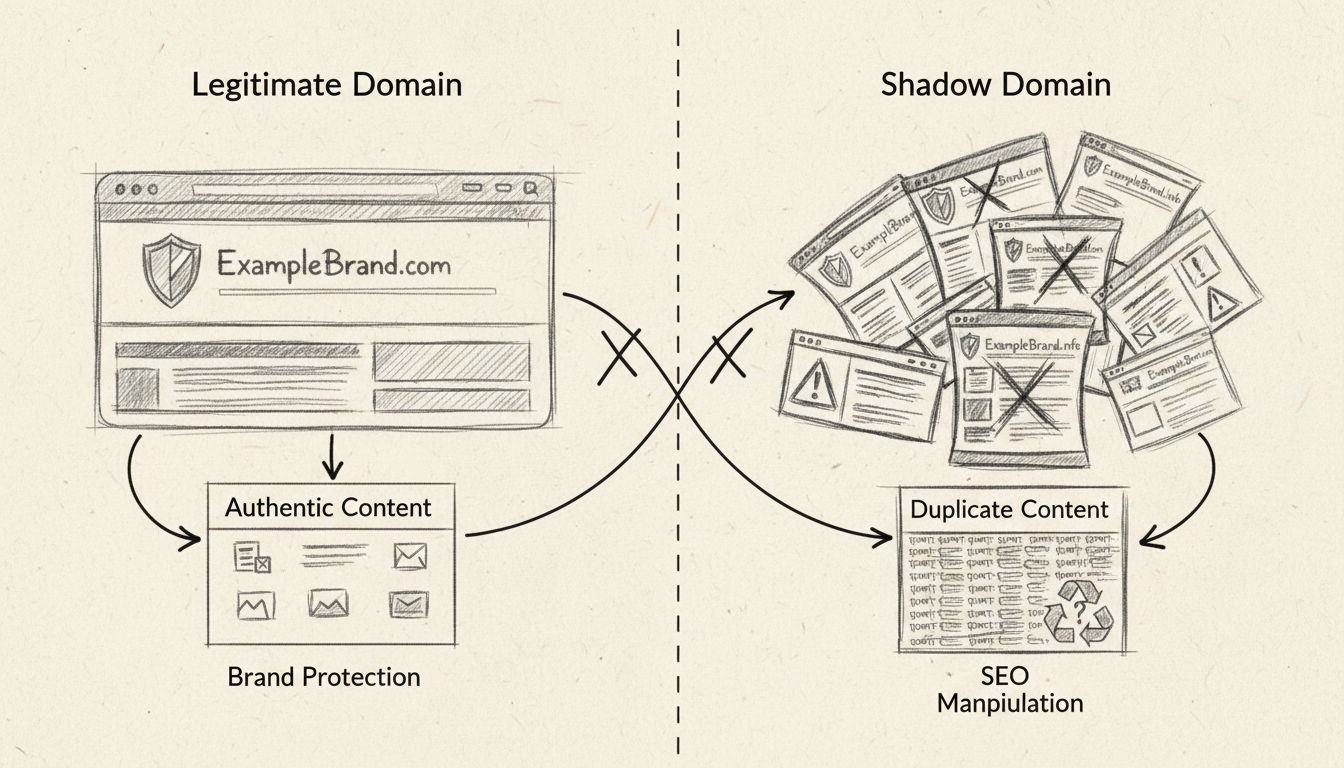
¿Son buenos los dominios sombra? Guía de riesgos, detección y prevención
Descubre por qué los dominios sombra son tácticas dañinas de SEO de sombrero negro. Conoce los riesgos como sanciones de búsqueda, desvío de tráfico, confusión ...
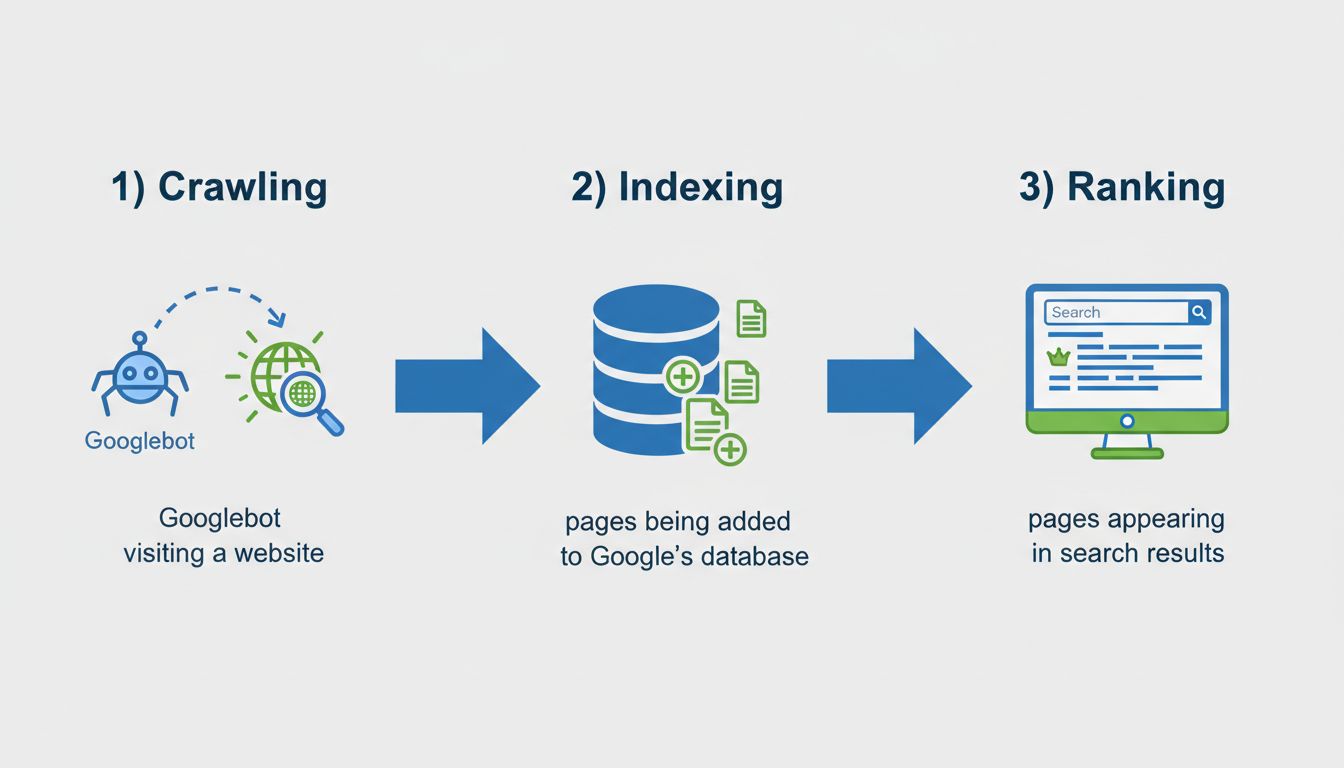
¿Qué significa cuando una página no está indexada? Guía completa sobre problemas de indexación en Google
Descubre qué significa la indexación de páginas, por qué Google no indexa algunas páginas y cómo solucionar problemas de indexación. Conoce soluciones técnicas ...
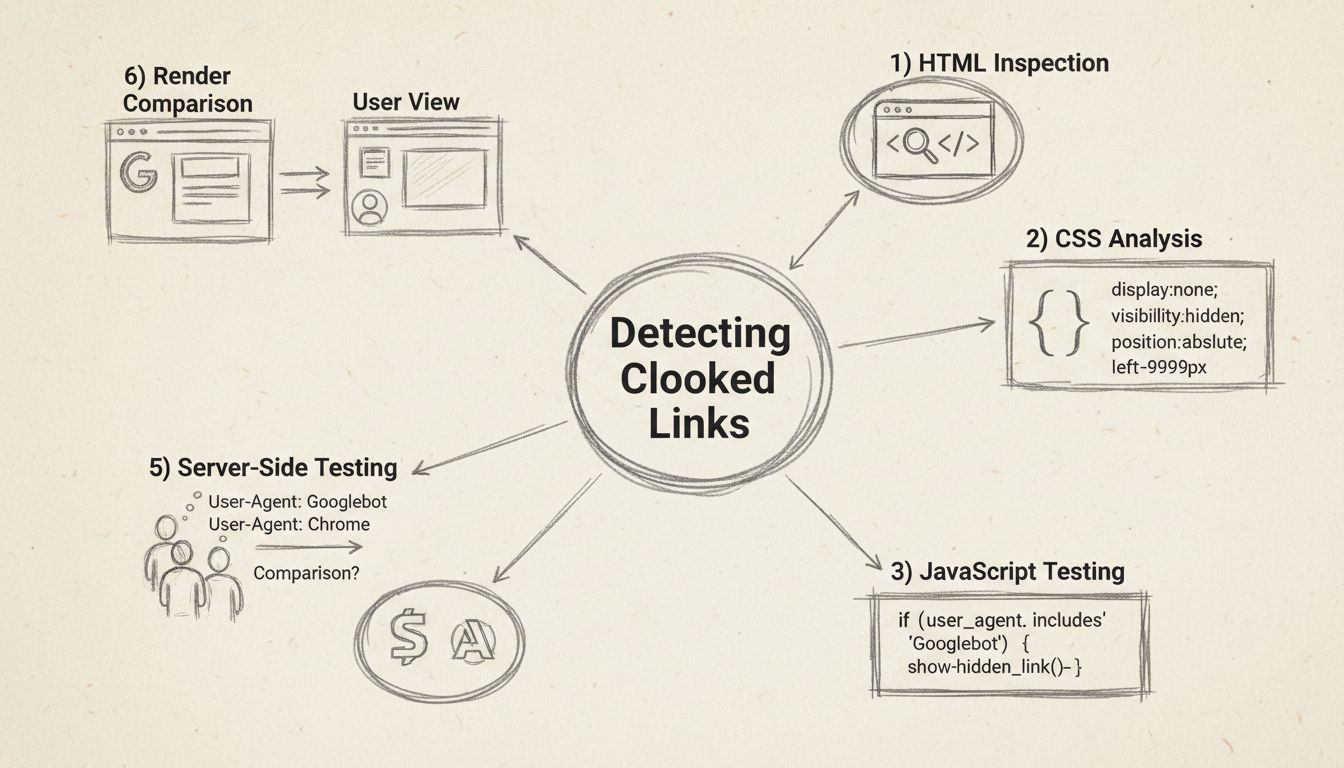
¿Cómo puedo encontrar enlaces disfrazados? Guía completa de detección
Aprende métodos comprobados para detectar enlaces disfrazados, incluyendo inspección de HTML, análisis de CSS, pruebas de JavaScript y herramientas SEO. Guía in...
11 min de lectura
¡Estarás en buenas manos!
Únete a nuestra comunidad de clientes satisfechos y brinda excelente soporte al cliente con Post Affiliate Pro.